Hmm, this got me thinking, and I'm probably restating what has already been said, but:
In the original two envelope problem, if you take the paradoxical reasoning, let us define the first envelope's value as X. Then, the second envelope's expected value depends on the probability that the pairing is {X/2,X} vs {X,2X}. The reasoning that leads to an expected second envelope value of 5X/4 implicitly assumes that the probability of these two pairs are equal for all X. But no probability distribution can satisfy this property. This necessarily implies that there exists some X such that the probabilities are not equal, which would affect the expected value of the second envelope.
The restating of the problem with nonuniform probability distribution solves this problem by making the distribution of envelope pairs explicit; this then shows that the expected value of the first envelope has to be infinite in order to get an expected value of the second envelope which is a constant factor larger. But since N*\inf == \inf for all nonzero finite N, this statement does not make the expected value of the second envelope actually larger than the first envelope, and in fact tells us nothing useful.
With the risk of boring everyone else reading this thread, here I go:
To clarify, I do not believe that switching an envelope everytime is better, I'd be crazy if I thought that, I'm just having a conversation about what is wrong in the common conclusion.
I'm skeptical of the infinity expected payoff approach, because:
* it just says "infinity is strange, by comparing things with infinity, we arrive at strange conclusions"
* concluding that two sets are equally better because their mean is infinity is clearly wrong. Take for example the pairs (1,2) , (2,4) , (3,6) , (4,8) ... When given a pair, the second number is always preferable, the fact that the set of the first numbers and the set of the second numbers have infinite means is irrelevant.
My solution is that the conclusion "Every value in infinite unbounded set A is less than a value in infinite unbounded set B implies that set B is preferable to set A" is not valid.
Again, I don't have the background to provide a formal proof of this, so I'll just give an intuitive one:
* The central tendency of a set is determined by its mean, in the unbounded "two envelope problem", the mean of both sets is infinity, thus it's impossible to compare them.
* Saying, in the reformulated problem, that, for every x, the fact that x < 11x/10 reaches no conclusion. Every value x is smaller than the means of the sets, by comparing values smaller than the mean, no conclusion can be made.
Thus, the comparison x < 11x/10 can't be used to say that the other envelope is better than the one you picked.
* it just says "infinity is strange, by comparing things with infinity, we arrive at strange conclusions"
I wouldn't call it "strange", that sounds too much like voodoo. When you're inserting infinity into your usual formulas the result is simply undefined, because addition etc. is only defined on reals. When you're disguising infinity as "x" and continue calculating, you seem to get results, but they're wrong.
Let's go back a step. To determine which strategy is "better", we need some metric. Currently, we implicitely use the metric of expected value, which is useful in many areas, but doesn't give usable results here because it is infinite. We can reach some conclusions, but only if we're careful with our tools and formulas.
Remember, the expected value does not make any predictions about a single game, it's only useful if you're considering a very large sample. And once you do that, you'll notice that both strategies (switch or don't switch) are equal, because you'll have an infinite payoff either way and it doesn't get any better than that.
However, once you opened an envelope, it's still "better" to switch (1.1*x), this conclusion avoided the use of infinity and is thus valid. How is that possible? Because "better" means "higher expected value", which is only meaningful for a large sample. And we've used a conditional probability; the result is useful only as long as the condition remains the same.
Let's say you're playing the game 1000 times, each time you open the first envelope and read the number 64 (if you don't, discard the game and try again). If you stick to that envelope, you'll end up with 64.000. If you switch each time, you can expect to hold about 70.400 in your hands. True result.
Now we can't conclude "so switching is the better strategy, right?", because then we're randomly pairing up partial values. You correctly said that that's not meaningful, a proof follows.
p4wn3r wrote:
My solution is that the conclusion "Every value in infinite unbounded set A is less than a value in infinite unbounded set B implies that set B is preferable to set A" is not valid.
Consider the sets A and B, both being the sets of all integers. Let's pair their elements up to see which is larger:
..., (-2, -1), (-1, 0), (0, 1), (1, 2), ... -> each element of B is strictly larger
..., (-1, -2), (0, -1), (1, 0), (2, 1), ... -> each element of A is strictly larger
Sorry a little slow, I am (all in response to stuff on page 37)
rhebus:
The distribution is not a small skewed discrete probability distribution. But it could be if the outer feels like it. You have shown that there are cases where it is indeed advantageous to guess second, and since I guess it is reasonable to assume that there that this has a finite chance of happening then it is indeed advantageous to guess second for all distributions on average. (Since in no case can it be beneficial to guess first).
Tub:
I agree it seems to be non precisely defined problem, and that stems from the human behavior involved, but I think the spirit of the problem is accurately presented and most things can be inferred.
I do not know if it is safe to assume that the numbers have a finite range. For example I often pick 10^100 or even negative infinity just to fuck with people.
I don't think Case A is the correct one, you cannot figure out how a person will pick a number unless you are Derren Brown :). Case C looks like the real case.
p4wn3r:
That is a very interesting paradox, thank you.
Warp:
You have shown that it is a contradiction, but you have not shown the error in the reasoning of it being 5/4x expected (hence the paradox).
Remember, the expected value does not make any predictions about a single game, it's only useful if you're considering a very large sample. And once you do that, you'll notice that both strategies (switch or don't switch) are equal, because you'll have an infinite payoff either way and it doesn't get any better than that.
The expected infinite payoff cannot be used to prove the equality of both strategies. We can prove it by the symmetry of the two envelope problem.
In my example, {(1,2), (2,4), (3,6), (4,8), ... } you're asked if it's better to pick the first or the second number. For every pair you get, it's better to choose the second number, even when you expect infinite payoffs for both sets.
Evaluating gain - loss in a set with infinite mean would yield infinity - infinity, which is undefined, like you said. So, it cannot be used to prove anything, nor that a strategy is better or if they are equally good. The fundamental difference between these cases is that the envelope problem is symmetrical, making it easy to see both strategies are equal.
Taken from the Wikipedia article:
"However, Clark and Shackel argue that this blaming it all on 'the strange behaviour of infinity' doesn't resolve the paradox at all; neither in the single case nor the averaged case. They provide a simple example of a pair of random variables both having infinite mean but where one is always better to choose than the other."
Taken from the Wikipedia article:
"However, Clark and Shackel argue that this blaming it all on 'the strange behaviour of infinity' doesn't resolve the paradox at all; neither in the single case nor the averaged case. They provide a simple example of a pair of random variables both having infinite mean but where one is always better to choose than the other."
I disagree here with Clark and Shackel: it is exactly what resolves the paradox. Misusing infinity in expected values is faulty reasoning, and it's no less faulty to say that the second variable in {(1,2),(2,4),(3,6)...} has a higher expectation therefore it's a better choice. Even if the result is correct, the reasoning is faulty.
I have a question though:
Consider the St Petersburg lottery, which pays out $1 half of the time, $2 1/4 of the time, $4 1/8 of the time, $8 1/16 of the time etc. Such a lottery has an infinite expected payout.
If I said I was to run a St Petersburg lottery once to get a number X, and give you the choice of X or 2X, you would clearly take 2X. But if I were to run it twice, and get two numbers X and Y, and give you the choice of X or 2Y, should you choose 2Y? Is it necessarily better than X? Or is there no real difference between choosing one or the other?
We could develop this further with a different lottery: define the "Petrograd lottery" which pays out $1 2/3 of the time, $3 2/9 of the time, $9 2/27 of the time etc. Again it has an infinite expected payout; but is it better to go with this one or the St Petersburg lottery, or does it not matter? Supposing that the Petrograd lottery is better than the St Petersburg lottery, how many St Petersburg tickets would we wish to trade for a Petrograd ticket? Or vice versa?
Joined: 4/20/2005
Posts: 2161
Location: Norrköping, Sweden
I have two questions that are of some importance to my job, but they may prove an interesting challenge for you! (I don't know the anwer to them). I have looked for solutions to these two problems myself, but without any luck.
A 2-dimensional polygon with n vertices can be represented as an n*2 matrix (let's call it A), where each row in the matrix represents a vertix. Let us assume that the polygon is not self-intersecting. The elements in the left column are the X positions of the vertices, and the elements in the right column are the Y positions. You can draw the polygon by drawing lines from the vertix on row i to the one on row i+1, for i=1,...n-1. In the last step, connect the last and first vertices.
a)For any point (x,y) and a polygon represented in the way described above by the matrix A, provide an algorithm that checks if (x,y) is inside the polygon or not.
b)Assume you have two polygons represented by the matrices A and B. The intersection of A and B is a polygon C (at least I think so... please provide a counter example if I'm wrong). Provide an algorithm that gives the elements of C in terms of the elements of A and B. If A and B don't intersect, C should be the empty matrix.
Are the polygons assumed to be convex? If not, then the intersection in part (b) can be a disjoint union of two or more polygons.
Solution to part (a) for convex polygons:
For each line segment forming the boundary of the polygon, determine which side of the line the given point in on. The point is inside the polygon if and only if it is on the "correct" side of all of these lines.
If you allow non-convex and self-intersecting polygons:
Consider the triangles A1-A2-A3, A1-A3-A4, A1-A4-A5, and so forth. (If the polygon is convex, this forms a triangulation of the polygon.) A point is inside the polygon if and only if it is inside an odd number of these triangles. I'm not quite sure what to do if it's on the boundary of one or more triangles.
(Disclaimer: I am fallible, and thus I could be wrong about any or all statements in this post.)
Joined: 4/20/2005
Posts: 2161
Location: Norrköping, Sweden
Thank you for all your solutions.
The polygons don't have to be convex, so non-convex polygons might show up. Your solution for convex polygons looks simple and show run very fast when implemented in a computer program.
Nitrodon wrote:
Consider the triangles A1-A2-A3, A1-A3-A4, A1-A4-A5, and so forth. (If the polygon is convex, this forms a triangulation of the polygon.) A point is inside the polygon if and only if it is inside an odd number of these triangles. I'm not quite sure what to do if it's on the boundary of one or more triangles.
Interesting! I am curious to know how you came up with this.
In my attempt to generalize to non-convex polygons, I figured that it should be possible to triangulate any polygon, but I was getting nowhere in my attempts to find an algorithm to do the triangulation. At some point, I realized that I could allow the triangles to include some area outside the polygon, and another triangle would just cancel it out.
A better possibility I just thought of (and I'm not sure why I didn't think of it earlier): Consider a ray extending from the given point in any direction. The point is inside the polygon if and only if the ray intersects an odd number of edges. If it goes through a vertex, this counts as one intersection, even though two edges are involved.
Joined: 3/10/2004
Posts: 7698
Location: 🇫🇮 Finland
Randil wrote:
a)For any point (x,y) and a polygon represented in the way described above by the matrix A, provide an algorithm that checks if (x,y) is inside the polygon or not.
That's a basic problem of computer graphics (and geometry in general). The basic algorithm is: Trace a line (eg. a line towards the positive x direction) from (x,y) and count how many polygon edges it intersects. If it intersects an odd amount, it's inside, else it's outside.
Algorithmically the problem can be simplified by translating all the points so that (x,y) ends up at (0,0). After that it suffices to determine which polygon edges intersect the positive x axis.
Determining if a polygon edge intersects the x axis is trivial (one endpoint has a negative y and the other has a positive y). Once you have determined that, you have to see if it intersects it on the positive side. This can be determined with a cross-product of the two vertex points of the edge (its sign will determine the answer).
Note that there's a small catch in that algorithm, which happens if a vertex point is exactly on the positive x axis (after the translation). You have to make sure you don't count the two edges sharing that vertex points as both intersecting the x axis. (This can be done either by testing if one of the vertex y coordinates is >=0 and the other <0, or alternatively by multiplying the vertex y coordinates by 2 and adding 1, especially if using integer coordinates, to force them to be unequal to the y coordinate of the tested point.)
b)Assume you have two polygons represented by the matrices A and B. The intersection of A and B is a polygon C (at least I think so... please provide a counter example if I'm wrong). Provide an algorithm that gives the elements of C in terms of the elements of A and B. If A and B don't intersect, C should be the empty matrix.
If polygons A and B can be concave, their intersection may produce more than one polygon. This is a much more complicated problem (but obviously not unsolvable).
a) If in doubt, ask http://en.wikipedia.org/wiki/Point_in_polygon
The first two algorithms mentioned there are the most widespread solutions, for good reason. The first one is a bit faster, but you'll have to be more careful with corner cases (what if the line hits the vertex?). Nitrodon's triangle algorithm might work, too (I didn't check), but the point-in-triangle-calculations required are more expensive.
/edit: Hi Warp!
b) intersection of two non-convex polygons is complicated. Let's start with polygons A and B, the intersection consists of the (non-intersecting) polygons C1, ..., Cm.
One option is to check each edge of polygon A against each edge of polygon B, whereever they cross you'll have one vertex of one of the result polygons Ci. From there on, follow the edges of the "inner" polygon until you reach the next crossing and connect accordingly.
Unfortunately, the first part alone is O(n^2), and the second one isn't trivial, either (now which side is the "inner" side?). And there's still those corner cases where vertices coincide or where edges cross a vertex.
There are a couple of sweepline algorithms that can do it faster, but I don't remember the details.
Both problems are very fundamental algorithms of computer graphics, both well-researched with plenty of algorithms to use. I'm surprised you didn't find anything in your research.
Consider the following "game"...
There are N trials, and in each trial, either player A or player B is given a point. In F*N of the trials, the probability that A gets the point is 1/2. In (1-F)*N of the trials, A is given a point with probablility P > 1/2. The winner is the player with more points at the end of the game (to eliminate ties, assume N is odd).
Let p(F,N,P) be the probability that A wins. How does p(0,N,P) - p(F,N,P) behave as N becomes large?
Eh, not in a significant way. You can put a pretty good upper bound on the value that's a simple function of N. It's not a simple function of F or P, but we're not interested in them.
I saw this problem on a math forum, and for some reason it got deleted...
Draw two circles that intersect in two distinct points, and draw one of the common tangents and then the circle through both points of tangency and either point of intersection of the circles; prove that the radius of this third circle depends only on the radii of the first two, and not on their position.
I tried using coordinate geometry but ended up with some nested radicals or a quartic or something else scary.
I saw this problem on a math forum, and for some reason it got deleted...
Draw two circles that intersect in two distinct points, and draw one of the common tangents and then the circle through both points of tangency and either point of intersection of the circles; prove that the radius of this third circle depends only on the radii of the first two, and not on their position.
I tried using coordinate geometry but ended up with some nested radicals or a quartic or something else scary.
I've seen this problem before with tangent circles, I didn't know the radius remained the same when they intersected in two points. Anyway, here goes.
Let's call O the center of the first circle, O' the center of the second, I one of the intersection points, T and T' the points where the tangent line encounters each circle.
So, we have the pentagon OIO'TT'. Notice that, OI=OT, O'I=O'T' and OI // O'T' (they are both perpendicular to TT'). The problem is to find the radius of the circunference that contains the vertices of the triangle ITT' (I don't know the term in English, circunscribed?).
Using the formula for the area of the triangle: S = abc / 4R, so for this case: R = IT * TT' * IT' / 4S
Using the isosceles triangles and calling the angle ITT' = x and IT'T = y, we can conclude (I need to draw to show this better, I'm too lazy atm, it's not very hard to do):
IT = 2 OT * Sin(x), IT' = 2 O'T' * Sin(y), S = TT' * OT (Sin(x))^2 , Sin(x) = Sin(y) * (OT/O'T')^1/2
Putting all this in the formula, we get R = (OT * O'T' )^1/2. This means that the size of the radius we're looking for is the geometric mean of the radii of the two circles and doesn't depend on their position.
The problem is to find the radius of the circunference that contains the vertices of the triangle ITT' (I don't know the term in English, circunscribed?).
Circumscribed. In full, the problem is to find the radius of the circle which is circumscribed around the triangle ITT'.
Nice work.
The problem is to find the radius of the circunference that contains the vertices of the triangle ITT' (I don't know the term in English, circunscribed?).
Circumscribed. In full, the problem is to find the radius of the circle which is circumscribed around the triangle ITT'.
Nice work.
Ah, thanks! Now I know that I was misspelling "circumference" all this time xD
This question inspired me to post another interesting geometry question here. Let's see if anyone here can crack the infamous Lidski triangle.
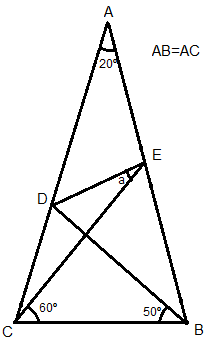
Consider the triangle ABC, where AB = AC and angle BAC = 20º. We now mark the point D in AC so that CBD = 50º, and point E in AB so that BCE = 60º. Evaluate the value of the angle CED.
Now with an awesome picture from MS Paint!
Joined: 4/20/2005
Posts: 2161
Location: Norrköping, Sweden
I placed the triangle in a normal XY plane, with C at (0,0). I set point B to (1,0) (I can set it to any value >0, it has no effect on the angle a). Then I calculated the coordinates for points D and E by interpreting the edges in the triangle as straight lines (y=kx+m) and calculating where they intersect. Now I had the coordinates for all nodes in the triangle CED so it was trivial to find the angle a.
And now I came with a different answer (I made a mistake before): a = 26.9175 degrees. Is this right? Maybe my method won't work. With B at x position 1, my coordinates for D are (0.1289, 0.7310) and for E they are (0.7660, 1.3268).
It should be noted that I tried finding a the "normal way" by just adding up angles in each triangle and such. In the end I ended up with 4 unknown angles, including a, and I had 4 equations for them. The matrix for this system of equations was singular, which was weird. I probably made a mistake along the way, thought I carefully redid it and ended up with the same singular matrix.
The answer is not 26.9175, but it's close. It's probably due to rounding errors on the calculation of the sines and cosines. I think you can solve this analytically, but it's like killing a fly with a cannon. Even if you do find a geometric method to determine the exact values of the trigonometric functions, there's always the chance you can get with a lot of radicals that you need some amazing factorization to solve.
It's not possible to determine a only adding the angles, that's why the matrix for your system is singular, you need to add more conditions.
Joined: 4/20/2005
Posts: 2161
Location: Norrköping, Sweden
Is it possible to find the angle a without assuming any lengths or coordinates and without using any trigonometric functions? I think I need a push in the right direction, I've spent 2-3 hours trying to solve this, without any luck. It's a fun problem, so I'd like to be able to solve it!
The 4 angles I have not found are BDE, ADE, a and AED.