If the fox simply seeks to the point on the circle that the duck is closest to, rather than trying to follow the direction the duck is going, then the contradiction goes away.
Build a man a fire, warm him for a day,
Set a man on fire, warm him for the rest of his life.
The ratio of the fox's speed to the duck's speed must be less than ~4.6033388488 (=1/cos(ψ) where ψ is the unique solution to tan(x)-x=π on [0,π/2]) for the duck to escape. Otherwise the duck cannot escape. Explanation is as below.
We model the problem so that the pond is enclosed by the unit circle, the duck starts at the center, and the fox is on the unit circle itself. The fox has speed 1 and the duck has speed r, where 0<r<1. Let ψ≈1.3518168043 be the unique solution to tan(x)-x=π on [0,π/2] and ζ≈0.2172336282 be cos(ψ). Note that ψ satisfies sin(ψ)=(π+ψ)cos(ψ). The diagram below shows the relation between ψ and ζ.
We want to show that the duck escapes if r>ζ and that the fox prevents the duck from escaping if r<ζ. (For various reasons I will not attempt to answer the case r=ζ.)
If r>ζ, then the duck escapes with the following strategy:
Phase 1: The duck moves towards the circle, keeping the center between itself and the fox, until it is r away from the center; this is the farthest distance from the center where the duck's maximum radial velocity is the same as the fox's radial velocity.
Phase 2: From the end of phase 1, the duck moves as follows:
1) If the fox does not move and remains opposite the duck with the center between them, the duck moves directly toward the circle, remaining opposite to the fox.
2) If the fox begins to move in one direction, the duck moves on a tangent (perpendicular to the line through the center and the duck) in a straight line and away from the direction which the fox is going; see diagram below. If after this, the fox reverses direction, then when it is again opposite to the duck, the duck resets its phase 2 strategy; it will be further away from the center than the previous time it started phase 2.
Let θ be the angle spanned by the duck's tangent path as in the diagram above. The duck's path distance is sin(θ), and the fox's path distance (long way around) is π+θ.
Thus the duck escapes if the ratio of distances sin(θ)/(π+θ) is less than r. The function sin(θ)/(π+θ) on [0,π/2], is in fact maximized at θ=ψ, with a value of sin(ψ)/(π+ψ)=cos(ψ)=ζ; this can be shown using calculus (*). Therefore sin(θ)/(π+θ)) ≤ ζ < r, and so we have shown that the duck can escape if r>ζ.
On the other hand, if r<ζ, then the fox prevents the duck from escaping with the following strategy:
Phase 1: The fox doesn't do anything until the duck tries to escape and reaches a distance of ζ from the center.
Phase 2: From the end of phase 1, the fox moves in the direction towards the duck (whichever direction reaches the point on the circle nearest the duck first). If the duck is opposite the fox, the fox may choose either direction. The fox always continues in the same direction unless:
1) the duck retreats to a distance less than ζ from the center, in which case the fox starts over from phase 1, or
2) the fox catches up to the duck by being at the point of the circle closest to the duck, in which case the fox moves to keep the duck between itself and the center; this is possible because the duck has a distance at least ζ from the center and r<ζ.
We may make assumptions about the positions of the duck and fox without loss of generality. Suppose at the start of phase 2, the duck is at (0,ζ), and the fox is supposed to move clockwise. We assume the fox's worst case; that is, the fox is at (0,-1) deciding to go clockwise.
In swimming to the circle, the duck's path sweeps out an angle of θ, clockwise with respect to the center (starting from an angle of 0 at (0,ζ) and ending on the circle at an angle of θ at (sin(θ),cos(θ)), with the condition that at no point is the path less than ζ away from the center. We may assume θ≥0; otherwise reflecting the path in the y-axis gives a better path.
There are two cases:
1) 0≤θ≤ψ
2) θ>ψ
Case 1 (diagram above): The shortest possible distance for the duck is a straight line. By the cosine law, the duck's path distance is sqrt(1+ζ2-2ζcos(θ)). The fox's path distance is π+θ. So the ratio of distances is sqrt(1+ζ2-2ζcos(θ))/(π+θ). It turns out by calculus (**) that sqrt(1+ζ2-2ζcos(θ))/(π+θ) is minimized on [0,ψ] at θ=ψ; the duck and fox path distances are the same as in the duck escape strategy above with θ=ψ (that is, sin(ψ) and π+ψ, respectively) and the ratio is ζ. So then sqrt(1+ζ2-2ζcos(θ))/(π+θ) ≥ ζ > r, and the fox catches up to the duck.
Case 2 (diagram above): The shortest possible distance for the duck, without retreating to a distance less than ζ from the center, is to go clockwise around the circle of radius ζ centered at (0,0) through an angle of θ-ψ, and then travel tangent to this smaller circle on a straight line to the unit circle. The duck's path distance is ζ(θ-ψ)+sin(ψ) and the fox's path distance is π+ψ+(θ-ψ). The ratio is then (ζ(θ-ψ)+sin(ψ))/((θ-ψ)+π+ψ) = ζ > r, and once again the fox catches up to the duck.
(*)
The derivative of sin(θ)/(π+θ) is ((π+θ)cos(θ)-sin(θ))/(π+θ)2; solving (π+θ)cos(θ)-sin(θ)=0 on [0,π/2] gives the unique solution θ=ψ, so there is a unique local extremum. This is a maximum since sin(θ)/(π+θ) is 0 when θ=0 and 2/(3π) < ζ when θ=π/2.
(**)
Let f(θ)=sqrt(1+ζ2-2ζcos(θ))/(π+θ)=sqrt(1+cos2(ψ)-2cos(ψ)cos(θ))/(π+θ). Then f2=(1+ζ2-2ζcos(θ))/(π+θ)2. Taking derivatives gives 2f'f=2g(θ)/(π+θ)3, where g(θ)=ζsin(θ)(π+θ)-(1+ζ2-2ζcos(θ)). Note that, using ζ=cos(ψ), we have g(ψ)=cos(ψ)sin(ψ)(π+ψ)-(1+cos2(ψ)-2cos2(ψ)) = sin2(ψ)-sin2(ψ) = 0.
Now g'=ζcos(θ)(π+θ)-ζsin(θ)=ζ(cos(θ)(π+θ)-sin(θ)); solving g'(θ)=0 (that is, cos(θ)(π+θ)-sin(θ)) gives the unique solution on [0,π/2] of θ=ψ. So θ=ψ is the unique solution to g(θ)=0, and thus the unique solution to f'(θ)=0, on [0,π/2]. So θ=ψ is a global extremum of f(θ) on [0,ψ]. It is the global minimum since f(0) = sqrt(1+ζ2-2ζ)/π = (1-ζ)/π > ζ.
As a side note, θ=ψ isn't actually a local minimum of f(θ) on [0,π/2] despite the fact that f'(ψ)=0; θ=ψ is an inflection point. Thus there are straight lines to points further clockwise that have better distance ratios for the duck. However, these lines necessarily approach the center closer than ζ; the fox's strategy calls for starting over from phase 1 in this case.
Bobo the King wrote:
By the way, I'm still a little confused about the duck's straight line strategy. In the instant before the duck reaches the shore, it would seem to me that the duck would do just a little bit better if it changed course to head straight for the shore. If it did so, it would end up a little bit ahead of the fox. Even though I understand all of the reasoning above and in my previous post, it seems very strange to me that there might be another strategy not based on a straight line that results in the duck being farther ahead of the fox.
If the fox is committed to a direction, heading straight for the shore is never the optimal strategy unless the fox has infinite speed.
In short, suppose that the duck is some fixed small distance d from the nearest point on shore. With a small enough d, the shore is essentially a straight line. Now suppose that the duck, instead of heading to the nearest point, heads to a point some distance h away from the nearest point, away from the fox's direction. Then the ratio of the change in distance is (sqrt(d2+h2)-d)/h = h/(sqrt(d2+h2)+d) → 0 as h→0. So there is a sufficiently small h which makes the ratio of the ducks's path distance to the fox's path distance smaller (which is good for the duck). In other words, the fox's path adds h and the duck's path adds sqrt(d2+h2)-d, which rapidly vanishes relative to h.
The classic challenge, in which you have to determine the probability that a quadrilateral constructed from points selected at random in unit squares of each quadrant, is very difficult. I tried finding a closed-form solution but gave up when writing and evaluating the integrals proved difficult. I also had a hard time splitting up the problem into disjoint probabilities that could be added or multiplied.
So I cheated. I set up an Excel spreadsheet that picks 10,000 sets of eight numbers (our four coordinates) at random. I produced additional columns that returned booleans based on whether three adjacent points formed a concave or convex region as well as another column that checked whether all four were convex. I then refreshed the numbers about 30 times and took the mean and standard error of the output. I can now say with good confidence that the probability that the quadrilateral is convex is 0.9086 + 0.0004.
I may continue this analysis with an even larger set of random numbers, but in any case, you are more than welcome to check a computed result against my Monte Carlo method.
I ended up doing a numerical integration and got a figure a few standard deviations outside your Monte Carlo simulation, a bit over 92%.
Odd. I just did an integration myself and obtained a smaller figure, about 87%. I'll edit this post in a few minutes to show my work.
Edit: So I obtained a solution. It doesn't agree with my earlier Monte Carlo simulation or aflech's result, but at least we're all in the same ballpark. Here's my work.
First, define the following coordinates:
xI
yI
xII
yII
xIV
yIV
These correspond to the x- and y-coordinates of three of our points. The subscripts indicate which quadrant each resides in. NOTE: I found it much easier to work with all positive numbers. Even though xII is in the second quadrant, I am taking it to be the positive distance from the y-axis. Likewise for yIV and the x-axis. I encourage you to draw some pictures as you read my argument below.
We wish to find the probability that these three points form a concave portion of the quadrilateral. We may pick xII, yII, and xIV as we please and, through suitable choices of the remaining variables, concave portions can be admitted. Therefore, we may write
xII ∈ (0, 1)
yII ∈ (0, 1)
xIV ∈ (0, 1)
With yIV, we encounter our first nontrivial restriction. We must pick yIV such that the line adjoining points II and IV passes above the origin-- otherwise, no convex region can be created and the probability is zero. It can be shown that this condition is equivalent to
yIV ∈ (0, yII*xIV/xII)
Next, we have a restriction on xI. This must lie between 0 and the x-intercept defined by the line adjoining points II and IV. This condition can be written as
xI ∈ (0, yII*(xII+xIV)/(yII+yIV) - xII)
Only one restriction left. We demand that yI lie below the line adjoining points II and IV for the now-given value of xI. This condition is...
yI ∈ (0, yII - (yII+yIV)/(xII+xIV)*(xII+xI))
Welp, that's a monster. All this needs to be plugged into a sextuple-integral. I guess I'll write it out in monospaced text in the hopes that it will be more readable:
The integral of
the integral of
the integral of
the integral of
the integral of
the integral of
1 dy_I dx_I dy_IV dx_IV dy_II dx_II
as y_I ranges from 0 to y_II - (y_II + y_IV)/(x_II + x_IV)*(x_II + x_I)
as x_I ranges from 0 to y_II*(x_II + x_IV)/(y_II + y_IV) - x_II
as y_IV ranges from 0 to y_II*x_IV/x_II
as x_IV ranges from 0 to 1
as y_II ranges from 0 to 1
as x_II ranges from 0 to 1
I'm sure the integral isn't that hard to evaluate but after setting it up, I decided I'd spare myself that agony and used my calculator. It spit out an exact answer of (2*ln(2)-1)/12 or about 0.0322.
Now, that's the probability that just one side is concave. It can be easily seen that no more than one region of a quadrilateral that doesn't self-intersect (like this one) can be concave. As such, we simply take this probability and multiply it by four to find the probability that any of the four sides is concave. Subtract this value from 1 to obtain (4 - 2*ln(2))/3 ≈ 0.8712.
Hey, what can I say? I tried.
Edit 2: I forgot to mention that my prediction of P(one region concave) = 0.0322 does not agree with my Excel spreadsheet. That's showing a probability of something like 0.0228 + 0.0002. I have no idea if that would help anyone figure out the real solution.
Thanks for the link! I wanted to figure out where I went wrong. Laurent Lessard's proof is (of course) more elegant than mine (though I think my variables were easier to keep track of). The key difference between our proofs is that he exploited a symmetry, stating that there is an equal probability that the triangular region defined by the x- and y-intercepts will lie in the first quadrant (greater than zero probability of concavity) as that it will lie in the third quadrant (zero probability of concavity). Lessard also computed the area of this triangle directly, avoiding the two inner integrals I produced.
After toying around with the bounds on my integrals, I found that the problem was in my bounds on yIV. The key error that I made was assuming yIV is only bounded by the condition that yIV be less than yII/xII*xIV. For certain values of yII, xII, and xIV, this allows yIV to exceed 1, which is not allowed. Correcting this bound would be messy, so Lessard had the right idea by exploiting symmetry.
Okay, new challenge. A few years ago I had a landlady who was a little batty. She was usually nice enough, but was really into a bunch of New Agey bullshit. For example, What the &%@#! do We Know? was one of her favorite movies. Lest you think I'm being too gossipy, she actually wrote and self-published a book about how to rent out a room in your house and included several anecdotes involving me.
Anyway, she had a long-distance boyfriend named Jack. Jack once boasted to her that he had some psychic abilities. He could shuffle a deck of cards, put it face down in front of him, and predict with roughly 70 percent accuracy whether the next card would be red or black, placing the the revealed card in a corresponding pile to the left or right of the deck, depending on its color.
Of course, my first instinct was that Jack was totally full of it. I actually still think he was, but on further reflection, I realized I might be able to approach Jack's number using just a little strategy and no psychic abilities whatsoever. To maximize the probability of choosing the next card correctly, I could keep track of which pile of revealed cards, red or black, was taller. My method would be to always assume the next card is from the shorter pile or if the two piles are equal, without loss of generality, assume the next card is red. I suspect that consciously or not, Jack was doing something similar.
So my question is What percentage of cards, on average, can you correctly guess using this strategy? I'll assume equal numbers of red and black cards in the deck for simplicity.
A few extreme cases are worth considering. One can always correctly guess the last card, no matter the size of the deck, guaranteeing that you can beat 50 percent on average. For an infinitely large deck, the probability is exactly 50 percent because each overturned card offers no information on the state of the next card. And for a deck of just two cards, you can correctly guess the color of the cards 75 percent of the time. The fact that even in the best-case scenario you do just five percent better than Jack's boast leads me to believe he was full of it.
From there, the math gets tricky. I'll cover just two more cases: a deck of four cards and a deck of six cards.
With four cards, there are six ways of arranging the deck. I'll use A and B instead of red and black for better readability. I'll also assume the player's default strategy is to pick A when the piles are equal. Here are how all six possibilities play out, correct guesses in bold:
{A,A,B,B} -- 3 correct
{A,B,A,B} -- 4 correct
{A,B,B,A} -- 3 correct
{B,A,A,B} -- 3 correct
{B,A,B,A} -- 2 correct
{B,B,A,A} -- 2 correct
This gives a total of 17 correct guesses for every 24 overturned cards, a 70.83 percent success rate.
Now I'll repeat this analysis for a deck of 6 cards, which covers 20 possible shufflings:
{A,A,A,B,B,B} -- 4 correct
{A,A,B,A,B,B} -- 4 correct
{A,A,B,B,A,B} -- 5 correct
{A,A,B,B,B,A} -- 4 correct
{A,B,A,A,B,B} -- 5 correct
{A,B,A,B,A,B} -- 6 correct
{A,B,A,B,B,A} -- 5 correct
{A,B,B,A,A,B} -- 5 correct
{A,B,B,A,B,A} -- 4 correct
{A,B,B,B,A,A} -- 4 correct
{B,A,A,A,B,B} -- 4 correct
{B,A,A,B,A,B} -- 5 correct
{B,A,A,B,B,A} -- 4 correct
{B,A,B,A,A,B} -- 4 correct
{B,A,B,A,B,A} -- 3 correct
{B,A,B,B,A,A} -- 3 correct
{B,B,A,A,A,B} -- 4 correct
{B,B,A,A,B,A} -- 3 correct
{B,B,A,B,A,A} -- 3 correct
{B,B,B,A,A,A} -- 3 correct
That's a total of 82 correct guesses for every 120 cards, a 68.33 percent success rate, already a little worse than Jack's claim.
And that's as far as I've gotten. Based on this very short trend (75 --> 70.83 --> 68.33), it appears that the success rate crashes fairly rapidly toward 50 percent as the deck size increases. In this sense, 52 would be "closer to infinity than to 2". Can anyone confirm this? What is the approximate probability of success using this strategy on a deck of 52 cards?
I suggest beginning by writing a computer program to confirm my results above and approximating the asymptotic behavior. Is it a negative exponential? An inverse power relation? Something else? Compute the first ten or so results, then extrapolate this out to 52 cards. (There are about 500 trillion different ways of arranging 52 cards distinguished only by their face color, which is at the upper limit of what can be calculated by supercomputers, so unless you can find an exact formula, it would be wise to do an extrapolation.)
I am pretty convinced the probability would tend to 50/50 as the pile of cards gets large.
If you have a completely random pack of N cards of two equally likely colours (ie a pack of N Bernoulli trials with p=1/2) then the standard deviation in the number of red cards in the pack is of the order sqrt(N). Of course this is not the case, but the point is that when N is enormous, for most of the time the number of cards in the two piles are going to be within sqrt(N) of each other, and hence the fact that one pile is bigger than the other gives you a negligibly better than 50% chance of guessing correctly.
One way you could attack this analytically is a Pascal's Triangle-like formula that works out the N reds, M blacks scenario from the N-1 reds, M blacks scenario and the N reds, M-1 blacks scenario. That probability will be given by:
p(N, M) = (N/(N+M))*p(N-1, M) + (M/(N+M))*p(N, M-1)
You could then build up a triangle of results quickly, but it would still take hundreds of calculations to get to p(26, 26).
EDIT: okay that formula doesn't work because it just produces a triangle full of ones. I don't know whether the formula just needs to be tweaked or whether the idea is totally wrong.
I am pretty convinced the probability would tend to 50/50 as the pile of cards gets large.
Better than that, based on the two examples I outlined and a little reasoning, I'm pretty convinced that you can do better than 50/50 every time you play.
Suppose the piles are even (maybe at the start of the game). Your goal is to finish the game while at least breaking even. You wager the first card is red. If it is, great. If not, you lose a "point" but now wager that the next card will be red (since the red stack is necessarily shorter). This process repeats itself-- if the next card is red, great, you're back to even, and if not, you again wager that the next card will be red. The idea is that if you are at a deficit of red cards, the remaining red cards must eventually show up somewhere in the main pile. You're sure to eventually get back to 50/50 regardless of what cards you draw because even in the worst case scenario, you will be down by n (red) cards with exactly n cards remaining, bringing you back to 50/50.
thatguy wrote:
One way you could attack this analytically is a Pascal's Triangle-like formula that works out the N reds, M blacks scenario from the N-1 reds, M blacks scenario and the N reds, M-1 blacks scenario. That probability will be given by:
p(N, M) = (N/(N+M))*p(N-1, M) + (M/(N+M))*p(N, M-1)
You could then build up a triangle of results quickly, but it would still take hundreds of calculations to get to p(26, 26).
EDIT: okay that formula doesn't work because it just produces a triangle full of ones. I don't know whether the formula just needs to be tweaked or whether the idea is totally wrong.
It sounds like you're trying to prove this by induction. I had some trouble with that tactic since I don't yet know of a way to generate a list of permutations of n+2 cards from a list of permutations of n cards. As far as I can tell, the problem is nontrivial.
You have given me an idea, though. What if we ignore the first, say, 42 cards drawn and focus on the 2048 possibilities for the last ten cards to be drawn. (Note that by doing it this way, we no longer necessarily have an even number of red and black cards.) Assume that all of the player's net score comes from these last ten cards. Assign a probability to each possibility, multiply by the calculated final score, and then add them all up to find a good estimate on the overall efficiency of this guessing method. The error in this estimate should be under 0.5% because we are neglecting as negligible cases where the last eleven cards are all red or black.
I'll try that approach later today.
When one gets a bit acquainted with Mersenne primes, knows what they are, sees the list of them, knows of the GIMPS project to find them and so on and so forth, they give the feeling that it should be obvious that there are infinitely many of them. Sure, they get rarer and rarer as you go higher in the set of natural numbers, but there doesn't seem to be any intuitive reason why there wouldn't be an infinite amount of them. (After all, primes themselves get rarer and rarer as you go up the number line, yet there are infinitely many of them.)
Thus it becomes somewhat of a surprise that the answer to the question of whether there are infinitely many Mersenne primes is actually unknown, an unsolved problem in mathematics. Why wouldn't there be infinitely many of them?
But, of course, as long as you can't prove there are, you can't say so. Assertions in mathematics cannot be made based on intuition and gut feeling.
But I suppose this isn't really a challenge nor a question (unless somebody feels like commenting on it, of course). So here's something completely unrelated:
I was playing this online Texas Hold'em game (which only uses play money, not real), and a situation came up where there were four players at the table, and three of them got King-Queen suited, and in addition to that there were 10, Jack and an Ace on the table (besides two other cards). In other words, they all got ace-high straights (but not straight flushes, though, as the 10, J and A were not suited). They split the pot three-way.
This is highly unusual and really, really rare. So I was wondering what the odds are. More specifically:
1) In a four-player game of Texas Hold'em, what are the odds that three of them will get King-Queen suited as their hand cards?
2) What are the odds that, in addition to the above, they all get ace-high straights (iow. 10, J and A hit the table; the two other cards don't matter). No straight flush (nor full houses), though, so those situations don't count.
The odds preferably in the form "1 in N".
And that's as far as I've gotten. Based on this very short trend (75 --> 70.83 --> 68.33), it appears that the success rate crashes fairly rapidly toward 50 percent as the deck size increases. In this sense, 52 would be "closer to infinity than to 2". Can anyone confirm this? What is the approximate probability of success using this strategy on a deck of 52 cards?
There is an exact probability, and it is 3724430600965475 / 6446940928325352 (about 57.7705%).
The exact formula for 2n cards (n red and n black) is 1/2 + (4n/C(2n,n) - 1)/(4n). The first few values of n agree with Bobo the King's calculations. Approximations for various n based on this formula, showing that this approaches 1/2 as n approaches infinity:
Plugging in the asymptotic formula C(2n,n)~4n/sqrt(pi*n) gives the approximation 1/2 + (sqrt(pi*n) - 1)/(4n) for large n, which is another way to show that the limit is infinity.
The long explanation for this is as follows:
The best strategy is: for each card, choose the color which has more cards remaining; since you make a choice at each stage, the aim is to maximize the expected number of cards guessed correctly for each card alone. When there are an equal number of red and black cards, it doesn't matter what you choose; the long-term success probability will not be affected. For simplification purposes, I will assume that in this case you choose red and black with equal probability (1/2 each).
It turns out that there is a combinatorial approach to this problem. Model the deck as a path of up and right steps starting from (0,0) and ending at (n,n) (such as shown in https://i.stack.imgur.com/vGlBj.gif for n=1 to 3) where you go through the deck and go up if the card is red and right if the card is black. Then there is a surprising relation between the expected number of correct guesses (and thus the long-term success probability) and the number of times this path contacts the line y=x (henceforth called "the diagonal").
Following the strategy above, consider each time the path goes between contact points on the diagonal, say, from (a,a) to (b,b). At (a,a), the random choice of red or black adds 1/2 to the expected number of correct guesses so far. After this card, you choose black (if it was red) or red (if it was black) until the path reaches (b,b); this adds b-a correct guesses. Thus, from (a,a) to (b,b), the expected number of correct guesses so far is increased by b-a + 1/2.
Summing over the whole path gives as the expected number of correct guesses n + E/2, where E is the average number of contacts with the diagonal, other than at (n,n), over all such paths from (0,0) to (n,n). So the long-term success probability is (n + E/2)/(2n) = 1/2 + E/(4n). The problem then becomes one of calculating E.
Generating functions
A Dyck path is an up-right path from (0,0) to (n,n) that never goes below the diagonal. The generating function for Dyck paths is D(x)=(1-sqrt(1-4x))/(2x). I will define a "strict Dyck path" as a Dyck path which never contacts the diagonal except at (0,0) and (n,n). A strict Dyck path is just a Dyck path from (0,1) to (n-1,n), with an additional up-step added to the beginning and an additional right-step at the end. I also allow the strict Dyck path to acquire two orientations: one where it is above the diagonal and one where it is reflected so as to be below the diagonal. The generating function for strict Dyck paths on two orientations is 2xD(x) = 1-sqrt(1-4x).
Thus an unrestricted up-right path from (0,0) to (n,n) can be viewed as a sequence of k≥1 strict Dyck paths on two orientations, and the number of contacts is k. Normally, we take the generating function 1/[1-(1-sqrt(1-4x))] = 1/sqrt(1-4x), which indeed is the generating function for the sequence C(2n,n). On the other hand, we can take the bivariate generating function F(x,z)= 1 / [1 - (1-sqrt(1-4x))z], which in addition counts the number of the diagonal contacts other than (n,n) in the variable z.
To calculate the average number of contacts E, we first take the sum total of contacts, which we do by taking the derivative of F(x,z) in z and then setting z=1. Since d/dz F(x,z) = (1-sqrt(1-4x))/[1 - (1-sqrt(1-4x))z]2, this gives (1-sqrt(1-4x))/(1-4x) = 1/(1-4x) - 1/sqrt(1-4x). The coefficient of xn of this generating function is 4n - C(2n,n). Thus the average number of contacts E is 4n/C(2n,n) - 1. Substituting into 1/2 + E/(4n) gives the formula 1/2 + (4n/C(2n,n) - 1)/(4n), as above.
Warp wrote:
Thus it becomes somewhat of a surprise that the answer to the question of whether there are infinitely many Mersenne primes is actually unknown, an unsolved problem in mathematics. Why wouldn't there be infinitely many of them?
But, of course, as long as you can't prove there are, you can't say so. Assertions in mathematics cannot be made based on intuition and gut feeling.
Math is full of stuff like that.
Possible reasoning based on heuristics for why there could be infinitely many Mersenne primes (and finitely many Fermat primes) is given here: http://math.stackexchange.com/questions/838678/intuitively-what-separates-mersenne-primes-from-fermat-primes . Of course not a valid proof of anything, but one of the reasons that people use heuristics is because we know so little about some things in math.
Warp wrote:
1) In a four-player game of Texas Hold'em, what are the odds that three of them will get King-Queen suited as their hand cards?
2) What are the odds that, in addition to the above, they all get ace-high straights (iow. 10, J and A hit the table; the two other cards don't matter). No straight flush (nor full houses), though, so those situations don't count.
I'll answer this later if no one else does, but I have some questions. For (1), does it matter what the fourth hand is? Can it be anything, including the last King-Queen suited? For (2), do we ignore the fourth hand completely, as in, we can assume that it has been folded and plays no further part in the deal?
Also, as a question of interest, in the deal that you mentioned (three players with King-Queen suited, 10, J, A and two others on the table), do you remember if all three players have nut hands? That is, from their point of view, they all had a hand which from their point of view could never lose no matter what anybody else had? If so, that would have been very interesting. The usual result being that all three players go all-in and a huge amount of excitement is generated, only to end in a split pot anyway. :D
Fantastic work, FractalFusion! It will take me a few read-throughs to absorb it all. What I especially love is that the probability of guessing a card correctly is substantially better than 50 percent. I can easily believe that with some (possibly sub-conscious) card counting, confirmation bias, and a little bit of luck 58 percent could turn into 70 percent in someone's mind.
I'll answer this later if no one else does, but I have some questions. For (1), does it matter what the fourth hand is? Can it be anything, including the last King-Queen suited?
Good question. Since in this situation the fourth player also getting a KQ would have been rather extraordinary, the question would have been about all four players getting it, rather than just three of them. I suppose that in the spirit of calculating the odds of this particular situation, the fourth player should not have KQ in hand. (Can have King or Queen, though.)
For (2), do we ignore the fourth hand completely, as in, we can assume that it has been folded and plays no further part in the deal?
Yes. Also in the spirit of the calculating the odds for the situation.
Also, as a question of interest, in the deal that you mentioned (three players with King-Queen suited, 10, J, A and two others on the table), do you remember if all three players have nut hands? That is, from their point of view, they all had a hand which from their point of view could never lose no matter what anybody else had? If so, that would have been very interesting. The usual result being that all three players go all-in and a huge amount of excitement is generated, only to end in a split pot anyway. :D
I happen to have a screenshot of the exact situation:
The first time I tried the multiple integration, I tried using a bunch of intermediate simplifications, and I got about 0.907; then I learned how to set up an ImplicitRegion in Mathematica to just numerically integrate in one step, and I guess I didn't figure out how to make it more accurate (that's where I got about 92% from).
1) In a four-player game of Texas Hold'em, what are the odds that three of them will get King-Queen suited as their hand cards?
Let's see if I can figure this out, at least partially.
There are 52 cards in the deck, so the probability of the first player getting a king or a queen is 8/52. After that there is only one correspondent card with the same suit, so the probability of getting it is 1/51.
After this there are three kings and queens left, so the second player getting one is 6/50, and then the other 1/49. And then likewise for the third player 4/48 and 1/47.
So if we just had three players, the probability of all of them getting KQ suited would be (8/52)*(1/51)*(6/50)*(1/49)*(4/48)*(1/47) = 192/14658134400 = 1/76344450 (ie. approximately 1 in 76 million.)
Now, the fourth player must not get both the remaining king and queen, as per the spirit of the question (because else the question would have been about four players getting KQ suited.) This is a bit trickier.
Taking this into account changes the probability by a really minuscule amount, but let's do it for completeness sake.
Basically the fourth player can choose two of the remaining 46 cards, except for one particular pair. There are "46 choose 2" possible ways to get two cards, ie. 46!/(2!*(46-2)!) = 1035. This means that the probability of the fourth player getting a pair of cards that's not the remaining KQ is 1034/1035.
Thus the total probability is 1034/(1035*76344450) = 1034/79016505750 = 11/840601125.
Now the community cards need to be 10, J, A, and two other cards. For the spirit of the question to remain valid, the 10, J and A must either be unsuited, or if they are suited it must be the fourth one (ie. not one held by any of the three players). And the two other cards must not make a straight flush with the 10, J and one of the player's pocket cards. In other words, the community cards must not have 9, 10 and J suited, with the same suit as the pocket cards of one of the players.
Uh... this becomes a bit complicated.
(I suppose that the community cards could be allowed to make something better than a straight, as long as it causes a split pot. In other words, full house, four of a kind or a straight flush that's smaller than king high. Also flush, as long as it doesn't make one of the players win. This would simplify the calculations. Maybe.)
If we allow ourselves to simplify things and don't care if one of the players wins, rather than it being a split pot, then it becomes easier. After all, the question is "what are the odds that all get KQ suited, and all get an Ace-high straight?" For simplicity, let's just allow flushes and straight flushes that are a win for one of the players.
However, even after this simplification I'm stuck. Basically I need to calculate all the possible ways of choosing 5 cards from a deck of 44 in such a manner that three of them are A, J and 10, and divide that number by the total number of ways to choose 5 cards from a deck of 44. That second number is 44 choose 5, but I'm stuck with that first number. (Complicating things is that one or two of the aces, jacks or tens may be in the hand of the fourth player...)
1)
However, even after this simplification I'm stuck. Basically I need to calculate all the possible ways of choosing 5 cards from a deck of 44 in such a manner that three of them are A, J and 10, and divide that number by the total number of ways to choose 5 cards from a deck of 44. That second number is 44 choose 5, but I'm stuck with that first number. (Complicating things is that one or two of the aces, jacks or tens may be in the hand of the fourth player...)
By division into cases (8 cases for combinations of either having or not having an Ace, a Jack, or a 10), it can be calculated by taking 44 choose 5 (all the hands), then subtracting the number of hands where an Ace appears, where a Jack appears, and when a 10 appears (including double counting); then adding the number of hands where neither an Ace nor Jack appear, neither Ace nor 10 appear, and neither Jack nor 10 appear, and then removing the cases where none of them appear.
Flogging it out gives me 41,584 possible hands with an Ace, Jack and 10.
Flogging it out gives me 41,584 possible hands with an Ace, Jack and 10.
If that number is correct, and if "44 choose 5" is 1086008, then the probability of getting A, J, 10 is 41584/1086008 = 5198/135751, or about 1 in 26.
If that's correct, then the probability of 3 players getting KQ suited, and the community cards having AJ10 is (11/840601125)*(5198/135751) = 57178/114112443319875, ie. approximately one in 1996 million (ie. about one in 2 billion).
Is this correct?
My take would be (not counting straight flushes).
(4 choose 3)*8/52*1/51*6/50*1/49*4/48*1/47 = 1 in 19 million probability that at least three out of four players get KQ suited.
AJT on board: I'd go for 46 unknown cards here.
(5 choose 3)* 3! * 4/46*4/45*4/44 = 1 in 23.7
4/46 is first card ace,4/45 second card king,4/44 third card ten, now add permutations (3!) and have these 3 cards in a flop of 5 (5 choose 3)
Both : about 1 in 453 million.
(4 choose 3)*8/52*1/51*6/50*1/49*4/48*1/47 = 1 in 19 million
I don't really understand why it has to be multiplied by (4 choose 3). Doesn't the 8/52 already take into account that one of the players may get any of the four kings or four queens?
I know you don't like easy challanges.
Here is very hard one (IMO)
Get unit square, then do following process:
1) Mark point on each side in clockwise order such that it splits in proportion a : b (clockwise)
2) Connect them to make new square.
3) Repeat.
Question is: what curves formed by verticies of squares when a : b ratio tends to zero?
1) Formulae
2) Is it some kind of known spiral?
3) Proof ofc
Illustration:
https://gist.github.com/realmonster/1435363efaf59cf114ab30bf60044501
That it forms a spiral can be proven by a geometric argument:
First, a remark: as you iteratively draw new inscribed squares, each new square will have the same geometric center as its predecessor. You only need to prove this for two squares (the outermost and its immediate successor); and it can be proven easily by noting that the diagonal vertices in each square will move the same amount but in opposing directions.
With that out of the way: we can now see that what changes with each successive square is its rotation and scale. Moreover, if at each step you zoom in and rotate counterclockwise so that the last square is a unit unrotated square, you can see that each new square rotates by the same amount, and shrinks by the same scale factor, as the previous square.
So the equations (in polar coordinates) of one of the vertices of the n-th square will be of the form
theta(n) = n*delta+theta_0
rho(n) = (scale^n)/sqrt(2)
Where n is the square number (0 being the outermost), and both delta and scale can be related to the ratio a:b, and theta_0 is the angle for the vertex you want. I will leave the rest as an exercise :-)
Edit: OK, I lied :-p.
Let r = a/b. Since a+b=1, we have that
b(1+a/b)=b(1+r)=1 => b = 1/(1+r)
=> a = r/(1+r)
Let R be the 'scale' factor in rho, above; R is better obtained from the square root of ratios of the areas of the first and second squares. The outer square has area 1; so we just need to compute the area of the inner square. Let c be the side of the inner square; this can be obtained by Pythagoras' theorem:
c^2 = a^2+b^2
Since c^2 is the area of the inner square, then R = c = sqrt(a^2+b^2) = sqrt(1+r^2)/(1+r).
Now to compute 'delta'. 'delta' is the angle subtended by a diagonal from the outer square and a diagonal from the inner square. Since the diagonals are at a 45 degree angle from the sides of the squares, 'delta' also is, equivalently, the angle between the sides of the squares. In our case, this is easier: it is the angle adjacent to b in the right triangle with sides a, b and c. So delta = arctan(a/b) = arctan(r).
Putting it all together:
theta(n) = n*arctan(r)+theta_0
rho(n) = ((sqrt(1+r^2)/(1+r))^n)/sqrt(2)
From this, we obtain:
n(theta) = (theta-theta_0) / arctan(r)
rho(theta) = ((sqrt(1+r^2)/(1+r))^((theta-theta_0) / arctan(r)))/sqrt(2) =
= exp( (theta-theta_0) * (ln(1+r^2)/2 - ln(1+r)) / arctan(r) )/sqrt(2)
Since we are interested in the limit r -> 0, and since exp is regular, we can take the limit of the exponent and substitute back:
lim{r->0} (ln(1+r^2)/2 - ln(1+r)) / arctan(r)
Both numerator (the difference of lns) and the numerator (arctan(r)) approach 0 in the limit; so by L'Hopital,
lim{r->0} (ln(1+r^2)/2 - ln(1+r)) / arctan(r) = lim{r->0} ((r-1)/((1+r)*(1+r^2))) / (1+r^2) =
= lim{r->0} (r-1)/((1+r)*(1+r^2)^2) = -1
So that
lim{r->0} rho(theta) = exp(-(theta-theta_0))/sqrt(2)




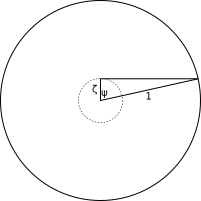 We want to show that the duck escapes if r>ζ and that the fox prevents the duck from escaping if r<ζ. (For various reasons I will not attempt to answer the case r=ζ.)
If r>ζ, then the duck escapes with the following strategy:
Phase 1: The duck moves towards the circle, keeping the center between itself and the fox, until it is r away from the center; this is the farthest distance from the center where the duck's maximum radial velocity is the same as the fox's radial velocity.
Phase 2: From the end of phase 1, the duck moves as follows:
1) If the fox does not move and remains opposite the duck with the center between them, the duck moves directly toward the circle, remaining opposite to the fox.
2) If the fox begins to move in one direction, the duck moves on a tangent (perpendicular to the line through the center and the duck) in a straight line and away from the direction which the fox is going; see diagram below. If after this, the fox reverses direction, then when it is again opposite to the duck, the duck resets its phase 2 strategy; it will be further away from the center than the previous time it started phase 2.
We want to show that the duck escapes if r>ζ and that the fox prevents the duck from escaping if r<ζ. (For various reasons I will not attempt to answer the case r=ζ.)
If r>ζ, then the duck escapes with the following strategy:
Phase 1: The duck moves towards the circle, keeping the center between itself and the fox, until it is r away from the center; this is the farthest distance from the center where the duck's maximum radial velocity is the same as the fox's radial velocity.
Phase 2: From the end of phase 1, the duck moves as follows:
1) If the fox does not move and remains opposite the duck with the center between them, the duck moves directly toward the circle, remaining opposite to the fox.
2) If the fox begins to move in one direction, the duck moves on a tangent (perpendicular to the line through the center and the duck) in a straight line and away from the direction which the fox is going; see diagram below. If after this, the fox reverses direction, then when it is again opposite to the duck, the duck resets its phase 2 strategy; it will be further away from the center than the previous time it started phase 2.
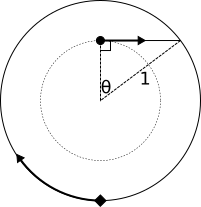 Let θ be the angle spanned by the duck's tangent path as in the diagram above. The duck's path distance is sin(θ), and the fox's path distance (long way around) is π+θ.
Thus the duck escapes if the ratio of distances sin(θ)/(π+θ) is less than r. The function sin(θ)/(π+θ) on [0,π/2], is in fact maximized at θ=ψ, with a value of sin(ψ)/(π+ψ)=cos(ψ)=ζ; this can be shown using calculus (*). Therefore sin(θ)/(π+θ)) ≤ ζ < r, and so we have shown that the duck can escape if r>ζ.
On the other hand, if r<ζ, then the fox prevents the duck from escaping with the following strategy:
Phase 1: The fox doesn't do anything until the duck tries to escape and reaches a distance of ζ from the center.
Phase 2: From the end of phase 1, the fox moves in the direction towards the duck (whichever direction reaches the point on the circle nearest the duck first). If the duck is opposite the fox, the fox may choose either direction. The fox always continues in the same direction unless:
1) the duck retreats to a distance less than ζ from the center, in which case the fox starts over from phase 1, or
2) the fox catches up to the duck by being at the point of the circle closest to the duck, in which case the fox moves to keep the duck between itself and the center; this is possible because the duck has a distance at least ζ from the center and r<ζ.
We may make assumptions about the positions of the duck and fox without loss of generality. Suppose at the start of phase 2, the duck is at (0,ζ), and the fox is supposed to move clockwise. We assume the fox's worst case; that is, the fox is at (0,-1) deciding to go clockwise.
In swimming to the circle, the duck's path sweeps out an angle of θ, clockwise with respect to the center (starting from an angle of 0 at (0,ζ) and ending on the circle at an angle of θ at (sin(θ),cos(θ)), with the condition that at no point is the path less than ζ away from the center. We may assume θ≥0; otherwise reflecting the path in the y-axis gives a better path.
There are two cases:
1) 0≤θ≤ψ
2) θ>ψ
Let θ be the angle spanned by the duck's tangent path as in the diagram above. The duck's path distance is sin(θ), and the fox's path distance (long way around) is π+θ.
Thus the duck escapes if the ratio of distances sin(θ)/(π+θ) is less than r. The function sin(θ)/(π+θ) on [0,π/2], is in fact maximized at θ=ψ, with a value of sin(ψ)/(π+ψ)=cos(ψ)=ζ; this can be shown using calculus (*). Therefore sin(θ)/(π+θ)) ≤ ζ < r, and so we have shown that the duck can escape if r>ζ.
On the other hand, if r<ζ, then the fox prevents the duck from escaping with the following strategy:
Phase 1: The fox doesn't do anything until the duck tries to escape and reaches a distance of ζ from the center.
Phase 2: From the end of phase 1, the fox moves in the direction towards the duck (whichever direction reaches the point on the circle nearest the duck first). If the duck is opposite the fox, the fox may choose either direction. The fox always continues in the same direction unless:
1) the duck retreats to a distance less than ζ from the center, in which case the fox starts over from phase 1, or
2) the fox catches up to the duck by being at the point of the circle closest to the duck, in which case the fox moves to keep the duck between itself and the center; this is possible because the duck has a distance at least ζ from the center and r<ζ.
We may make assumptions about the positions of the duck and fox without loss of generality. Suppose at the start of phase 2, the duck is at (0,ζ), and the fox is supposed to move clockwise. We assume the fox's worst case; that is, the fox is at (0,-1) deciding to go clockwise.
In swimming to the circle, the duck's path sweeps out an angle of θ, clockwise with respect to the center (starting from an angle of 0 at (0,ζ) and ending on the circle at an angle of θ at (sin(θ),cos(θ)), with the condition that at no point is the path less than ζ away from the center. We may assume θ≥0; otherwise reflecting the path in the y-axis gives a better path.
There are two cases:
1) 0≤θ≤ψ
2) θ>ψ
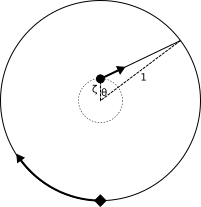 Case 1 (diagram above): The shortest possible distance for the duck is a straight line. By the cosine law, the duck's path distance is sqrt(1+ζ2-2ζcos(θ)). The fox's path distance is π+θ. So the ratio of distances is sqrt(1+ζ2-2ζcos(θ))/(π+θ). It turns out by calculus (**) that sqrt(1+ζ2-2ζcos(θ))/(π+θ) is minimized on [0,ψ] at θ=ψ; the duck and fox path distances are the same as in the duck escape strategy above with θ=ψ (that is, sin(ψ) and π+ψ, respectively) and the ratio is ζ. So then sqrt(1+ζ2-2ζcos(θ))/(π+θ) ≥ ζ > r, and the fox catches up to the duck.
Case 1 (diagram above): The shortest possible distance for the duck is a straight line. By the cosine law, the duck's path distance is sqrt(1+ζ2-2ζcos(θ)). The fox's path distance is π+θ. So the ratio of distances is sqrt(1+ζ2-2ζcos(θ))/(π+θ). It turns out by calculus (**) that sqrt(1+ζ2-2ζcos(θ))/(π+θ) is minimized on [0,ψ] at θ=ψ; the duck and fox path distances are the same as in the duck escape strategy above with θ=ψ (that is, sin(ψ) and π+ψ, respectively) and the ratio is ζ. So then sqrt(1+ζ2-2ζcos(θ))/(π+θ) ≥ ζ > r, and the fox catches up to the duck.
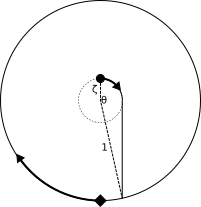 Case 2 (diagram above): The shortest possible distance for the duck, without retreating to a distance less than ζ from the center, is to go clockwise around the circle of radius ζ centered at (0,0) through an angle of θ-ψ, and then travel tangent to this smaller circle on a straight line to the unit circle. The duck's path distance is ζ(θ-ψ)+sin(ψ) and the fox's path distance is π+ψ+(θ-ψ). The ratio is then (ζ(θ-ψ)+sin(ψ))/((θ-ψ)+π+ψ) = ζ > r, and once again the fox catches up to the duck.
(*)
The derivative of sin(θ)/(π+θ) is ((π+θ)cos(θ)-sin(θ))/(π+θ)2; solving (π+θ)cos(θ)-sin(θ)=0 on [0,π/2] gives the unique solution θ=ψ, so there is a unique local extremum. This is a maximum since sin(θ)/(π+θ) is 0 when θ=0 and 2/(3π) < ζ when θ=π/2.
(**)
Let f(θ)=sqrt(1+ζ2-2ζcos(θ))/(π+θ)=sqrt(1+cos2(ψ)-2cos(ψ)cos(θ))/(π+θ). Then f2=(1+ζ2-2ζcos(θ))/(π+θ)2. Taking derivatives gives 2f'f=2g(θ)/(π+θ)3, where g(θ)=ζsin(θ)(π+θ)-(1+ζ2-2ζcos(θ)). Note that, using ζ=cos(ψ), we have g(ψ)=cos(ψ)sin(ψ)(π+ψ)-(1+cos2(ψ)-2cos2(ψ)) = sin2(ψ)-sin2(ψ) = 0.
Now g'=ζcos(θ)(π+θ)-ζsin(θ)=ζ(cos(θ)(π+θ)-sin(θ)); solving g'(θ)=0 (that is, cos(θ)(π+θ)-sin(θ)) gives the unique solution on [0,π/2] of θ=ψ. So θ=ψ is the unique solution to g(θ)=0, and thus the unique solution to f'(θ)=0, on [0,π/2]. So θ=ψ is a global extremum of f(θ) on [0,ψ]. It is the global minimum since f(0) = sqrt(1+ζ2-2ζ)/π = (1-ζ)/π > ζ.
As a side note, θ=ψ isn't actually a local minimum of f(θ) on [0,π/2] despite the fact that f'(ψ)=0; θ=ψ is an inflection point. Thus there are straight lines to points further clockwise that have better distance ratios for the duck. However, these lines necessarily approach the center closer than ζ; the fox's strategy calls for starting over from phase 1 in this case.
Case 2 (diagram above): The shortest possible distance for the duck, without retreating to a distance less than ζ from the center, is to go clockwise around the circle of radius ζ centered at (0,0) through an angle of θ-ψ, and then travel tangent to this smaller circle on a straight line to the unit circle. The duck's path distance is ζ(θ-ψ)+sin(ψ) and the fox's path distance is π+ψ+(θ-ψ). The ratio is then (ζ(θ-ψ)+sin(ψ))/((θ-ψ)+π+ψ) = ζ > r, and once again the fox catches up to the duck.
(*)
The derivative of sin(θ)/(π+θ) is ((π+θ)cos(θ)-sin(θ))/(π+θ)2; solving (π+θ)cos(θ)-sin(θ)=0 on [0,π/2] gives the unique solution θ=ψ, so there is a unique local extremum. This is a maximum since sin(θ)/(π+θ) is 0 when θ=0 and 2/(3π) < ζ when θ=π/2.
(**)
Let f(θ)=sqrt(1+ζ2-2ζcos(θ))/(π+θ)=sqrt(1+cos2(ψ)-2cos(ψ)cos(θ))/(π+θ). Then f2=(1+ζ2-2ζcos(θ))/(π+θ)2. Taking derivatives gives 2f'f=2g(θ)/(π+θ)3, where g(θ)=ζsin(θ)(π+θ)-(1+ζ2-2ζcos(θ)). Note that, using ζ=cos(ψ), we have g(ψ)=cos(ψ)sin(ψ)(π+ψ)-(1+cos2(ψ)-2cos2(ψ)) = sin2(ψ)-sin2(ψ) = 0.
Now g'=ζcos(θ)(π+θ)-ζsin(θ)=ζ(cos(θ)(π+θ)-sin(θ)); solving g'(θ)=0 (that is, cos(θ)(π+θ)-sin(θ)) gives the unique solution on [0,π/2] of θ=ψ. So θ=ψ is the unique solution to g(θ)=0, and thus the unique solution to f'(θ)=0, on [0,π/2]. So θ=ψ is a global extremum of f(θ) on [0,ψ]. It is the global minimum since f(0) = sqrt(1+ζ2-2ζ)/π = (1-ζ)/π > ζ.
As a side note, θ=ψ isn't actually a local minimum of f(θ) on [0,π/2] despite the fact that f'(ψ)=0; θ=ψ is an inflection point. Thus there are straight lines to points further clockwise that have better distance ratios for the duck. However, these lines necessarily approach the center closer than ζ; the fox's strategy calls for starting over from phase 1 in this case.








{kind=link}