2) Let's stick specifically to positive real numbers here - raising a negative number to a fractional power leads us into the murkier waters since these functions are multi-valued, and can only be defined via somewhat artificial branch cuts.
xy > eylnx implies:
eylnx > exlny
ylnx > xlny
lnx/x > lny/y
So the easiest way to visualise this is to draw a graph of f(x) = lnx/x, and then substitute in x and y. If f(x) > f(y), then xy > yx. Interestingly, this gives the relation a transitive property: If xy > yx, and yz > zy, then you can guarantee that xz > zx.
So the easiest way to visualise this is to draw a graph of f(x) = lnx/x, and then substitute in x and y. If f(x) > f(y), then xy > yx. Interestingly, this gives the relation a transitive property: If xy > yx, and yz > zy, then you can guarantee that xz > zx.
To take this just a little bit further, it can be shown with just a little calculus that lnx/x peaks at x = e and decreases thereafter. If both x and y are greater than e, then x^y > y^x if and only if x>y. Likewise, if both x and y are less than e, then x^y > y^x if and only if x<y. If x and y straddle e, f(x) must be compared directly with f(y).
On an unrelated note, here's a new math problem, which is not really a problem. I'm interested in very basic examples of algebraic geometry, specifically up to quadratic forms. I have a sort of obsession with solving systems of equations using the substitution method because when one encounters a system of equations with quadratic terms, the elimination and matrix methods offer no help. The substitution method is ironclad.
But it can also be tedious. As a simple example, consider an elastic collision in one dimension. We know kinetic energy and linear momentum are conserved, giving us two equations in two variables:
1/2*m_1*v_10^2 + 1/2*m_2*v_20^2 = 1/2*m_1*v_1f^2 + 1/2*m_2*v_2f^2
m_1*v_10 + m_2*v_20 = m_1*v_1f + m_2*v_2f
where m_1 and m_2 are the respective masses, v_10 and v_20 are the masses' initial velocities, and v_1f and v_2f are the masses' final velocities. (I know the underscores and carets are tiring to the eyes, but I don't wish to format the equations right now.) Given any four values-- typically m_1, m_2, v_10, and v_20-- that's just two equations and two variables and so all that remains is a little algebra.
Well, "a little algebra" can quickly become a nightmare. You end up with a quadratic equation in either v_1f or v_2f and a lot of coefficients flying around everywhere. It ends up being easier to just memorize the solution or...
... being clever with your physics. By recognizing that the physical process is subject to a time-reversal symmetry, you can determine that a particularly easy way of solving this problem involves entering the center of mass frame, negating the initial velocities, and then exiting the center of mass frame. Altogether, the solution looks like this:
v_com|G = (m_1*v_10|G + m_2*v_20|G)/(m_1 + m_2)
v_10|com = v_10|G - v_com|G
v_20|com = v_20|G - v_com|G
v_1f|com = - v_10|com
v_2f|com = - v_20|com
v_1f|G = v_1f|com + v_com|G
v_2f|G = v_2f|com + v_com|G
As you can see, the subscripts have become even more complicated. Here, the vertical bar stands for "relative to", G means ground (or the lab frame), and com means center of mass. On the bright side, there's not a squared term in sight! What was a quadratic equation becomes a linear system of equations. Granted, it's now seven equations and seven variables, but they're actually quite easy to solve since each equation only has a dependence on the ones that preceded it.
So that's the kind of thing I'm looking for. I can think of two similar physics problems that I haven't yet fully deciphered. First, what if an elastic collision takes place in two dimensions? Second, what about Compton scattering? In the case of Compton scattering, our three equations are
h*c/lambda + m*c^2 = h*c/lambda' + sqrt(m^2*c^4 + m^2*v^2/(1-v^2/c^2))
h/lambda = h/lambda'*cos(theta) + m*v/sqrt(1-v^2/c^2)*cos(phi)
0 = h/lambda'*sin(theta) - m*v/sqrt(1-v^2/c^2)*sin(phi)
where our variables typically are v and phi. This reduces to a simple equation:
lambda' - lambda = h/(m*c) * (1 - cos(theta))
This can be derived with the substitution method, but it takes about thirty minutes to an hour. (Of course, the elimination and matrix methods are again no help.) A textbook I referred to pointed out that the derivation can be significantly simplified by writing the conservation of momentum in vector form and taking the dot product between the first photon's momentum and the second photon's momentum, which naturally gives a single equation that does not involve phi. I think it's a nice trick, but I have a few issues with it. It's a math trick that must be memorized, not a physics trick, and it still leaves you with two nonlinear equations.
My question is whether there is a reliable method for solving quadratic equations in several variables, preferably a method that reduces the problem to a system of linear equations and if possible, one that can be given physical justification, as I did with the one-dimensional elastic collision example. Again, I know the answer lies somewhere in algebraic geometry, but I'm afraid I have no background in the subject and don't know where to start.
2) Let's stick specifically to positive real numbers here - raising a negative number to a fractional power leads us into the murkier waters since these functions are multi-valued, and can only be defined via somewhat artificial branch cuts.
xy > eylnx implies:
eylnx > exlny
ylnx > xlny
lnx/x > lny/y
So the easiest way to visualise this is to draw a graph of f(x) = lnx/x, and then substitute in x and y. If f(x) > f(y), then xy > yx. Interestingly, this gives the relation a transitive property: If xy > yx, and yz > zy, then you can guarantee that xz > zx.
To add to this, the graph of f(x) = ln(x)/x is as follows:
So the equation ln(x)/x = c has two solutions x1, x2 whenever 0 < c < 1/e (the maximum of ln(x)/x is at x=e with a value of 1/e; this is proved with calculus; ln(x)/x → 0 as x → ∞ as well), with 1 < x1 < e, and x2 > e. For example, when c = ln(2)/2, the two solutions are x1=2 and x2=4.
In fact, these two solutions are given exactly by x1 = e-W(-c) and x2 = e-W-1(-c), respectively, where W(x) and W-1(x) are branches of the Lambert W function; W(x) is the inverse of xex on -1 to ∞, and W-1(x) is the inverse of xex on -∞ to -1. This is because:
ln(x)/x = c
→ z/ez = c where x=ez
→ -ze-z = -c
→ -z = W(-c) or W-1(-c)
→ z = -W(-c) or -W-1(-c)
→ x = e-W(-c) or e-W-1(-c).
To answer the question, xy > yx for positive x,y if and only if at least one of the following is true:
@ y < x ≤ e,
@ e ≤ x < y,
@ y ≤ 1 < x,
@ 1 < x < e and y > e-W-1(-ln(x)/x),
@ x > e and y < e-W(-ln(x)/x).
Joined: 11/14/2011
Posts: 68
Location: Brookline, MA
Related to the current discussion here is a conjecture I made back in the year 2000 while I took Calculus in high school.
Conjecture:
dn/dxn x1/x has exactly n positive real zeroes, all simple.
(d^n x^(1/x))/(dx^n) = x^(-n + 1/x) (1 - n + 1/x)_n for (n element Z and n>=0 and x!=1/x)
Where (x)_n is the Pochhammer symbol and represents (x)(x+1)(x+2)...(x+n-1)
This formula is polynomial of 1/x of degree n which can be easily shown to have positive zeroes (when 1/x = 1-n+m), multiplied by a term which is zero at no point while x > 0. However, one of the zeroes is at 1/x = 0. I'd look into this more to figure out where the final zero is coming from, but I have to drive.
Build a man a fire, warm him for a day,
Set a man on fire, warm him for the rest of his life.
(d^n x^(1/x))/(dx^n) = x^(-n + 1/x) (1 - n + 1/x)_n for (n element Z and n>=0 and x!=1/x)
Where (x)_n is the Pochhammer symbol and represents (x)(x+1)(x+2)...(x+n-1)
That would be true if 1/x didn't have an x in it. Unfortunately d/dx xk= kxk-1 is only valid when k does not depend on x.
Regarding dn/dxn x1/x, I'm not sure how to prove that it has n simple zeroes (obviously everything has to be positive since it is only defined for x>0). I do know that something like this can be proven for dn/dxn e-x2 as follows:
The function y=e-x2 satisfies the differential equation y'=-2xy. Using this, we can show that y(n)=p(x)y, where p(x) is a polynomial of degree n. That means:
● y is infinitely differentiable everywhere.
● Since y has no zeroes, that means y(n)=0 only when p(x)=0, so y(n) has no more than n zeroes counting multiplicity.
● lim[x→-∞] y(n) = lim[x→∞] y(n) = 0 for all n.
Clearly y' has exactly one simple zero at x=0. Now suppose y(n) has n simple zeroes at x1, x2, ..., xn. Because they are simple zeroes, they cannot be zeroes of y(n+1). By the mean value theorem, there exists a zero of y(n+1) between each pair xi, xi+1. There also exists a zero less than x1 (mean value theorem on x0→-∞ and x1) and a zero greater than xn (mean value theorem on xn and xn+1→∞), which gives at least n+1 zeroes of y(n+1). Since there are no more than n+1 zeroes counting multiplicity, then these n+1 zeroes are the only zeroes and they are all simple.
I haven't figured out if this process works for dn/dxn x1/x yet.
----
By the way, there are a couple interesting problems on The Riddler this week.
Riddler Classic: Fill all the * entries with digits from 0 to 9 to make this long division correct. Numbers can't start with 0. There is only one solution and it can be done with pen and paper.
That is the easy problem. The hard problem is Riddler Express below.
Riddler Express: Cut the shape below into three pieces and reassemble them into a square.
I have a solution for Riddler Classic but I still haven't figured out Riddler Express yet.
Well, x^(1/x) = e^(log(x)/x) in the domain of interest.
Using a similar approach, this satisfies the differential equation y' = x^-2(1 - log(x))y
The form of this is not so nice. But the x^-2 bit shouldn't affect the roots, even under repeated differentiation (it will however ensure that there will always be a log and a constant, so there will always be exactly one root from each term).
So... that's the outline of a proof, but the only problem, is I can't seem to figure out a way to prove that roots will never repeat.
Build a man a fire, warm him for a day,
Set a man on fire, warm him for the rest of his life.
I haven't figured out if this process works for dn/dxn x1/x yet.
I think you can do it by changing variables.
y(x) = x1/x = eln x/x
y'(x) = (1/x2 - ln x/x2)y(x)
x2y'(x) = (1 - ln x)y(x)
Since x > 0, this suggests the change of variable x = eu. By the chain rule:
y'(x) = dy/dx = (dy/du) / (dx/du) = y'(u)e-u
Substituting the rest and rearranging you get
y'(u) = (1-u)e-uy(u)
By induction you can prove that
y(n)(u) = Pn(u)e-uy(u) [*],
where Pn(u) is an n-th degree polynomial.
Now to get back to y(n)(x), notice that
y'(x) = y'(u)e-u = (1-u)e-2uy(u)
y''(x) = d/du ( y'(u) e-u) e-u = (y''(u)-y'(u))e-2u
By substituting [*], you should be able to express y''(x) as a polynomial in u times e-3uy(u).
You should be able to prove by induction that
y(n)(x) = Qn(u)e-(n+1)uy(u),
where x=e^u.
The presence of e-(n+1)u does not affect your proof, since if y(u) never vanishes, neither does e-(n+1)uy(u). So Qn(u) must vanish, and this limits the number of zeros of y(n)(x) to n. Now you must prove that the limit is 0 at x going to 0 and infinity, I haven't done that, but you might be able to do it by looking at the assymptotics of the ODE. The rest of the proof is similar, the mean value theorem can still be applied, the only difference is that in the first zero you must invoke it between x0=0 and x1.
y'(u) = (1-u)e-uy(u)
By induction you can prove that
y(n)(u) = Pn(u)e-uy(u) [*],
where Pn(u) is an n-th degree polynomial.
I'm not sure about this. For example, I'm getting for y''(u):
y''(u) = -e-uy(u) + (u-1)e-uy(u) + (1-u)e-uy'(u)
= (u-2)e-uy(u) + (1-u)2e-2uy(u),
which isn't in the form written above (y(n)(u) = Pn(u)e-uy(u)).
Related to the current discussion here is a conjecture I made back in the year 2000 while I took Calculus in high school.
Conjecture:
dn/dxn x1/x has exactly n positive real zeroes, all simple.
It is probably provable that there are at least n roots by abusing Rolle's theorem, as there are essentially always going to be 'roots' (or something close enough to roots to enable Rolle's theorem to work) at 0 and infinity, and there are n-1 roots for n-1 (as an induction hypothesis).
y'(u) = (1-u)e-uy(u)
By induction you can prove that
y(n)(u) = Pn(u)e-uy(u) [*],
where Pn(u) is an n-th degree polynomial.
I'm not sure about this. For example, I'm getting for y''(u):
y''(u) = -e-uy(u) + (u-1)e-uy(u) + (1-u)e-uy'(u)
= (u-2)e-uy(u) + (1-u)2e-2uy(u),
which isn't in the form written above (y(n)(u) = Pn(u)e-uy(u)).
You're right. I somehow forgot the last term when I calculated y''(u) before. I'll see if I can get a change of variables that works.
Set dy/dx = 0: 1-lnx = 0, x = e
Therefore y = e1/e
Surprise e!
Is there a reason why precisely e appears in this case? I mean, is there a simple correlation with the definition of e, and the curve x1/x?
(I find it curious how e was first discovered when mathematicians wondered what happens when you calculate compound interest continuously over a period of time. Rather than resulting in infinite interest, as one might hastily think, the maximum amount of gains is finite. And e was the factor that popped up as the limit.
Well, that's nice. Just a curiosity? One number among others, that just happens to be the answer to this very particular question? Except that e turned out to be one of the most important and ubiquitous numbers in mathematics, as it tends to pop up very often in seemingly unrelated problems.)
Depends what you consider the definition of e. Most people are introduced to it through the following identity:
lim(n -> inf) (1+1/n)n = e
However, from an analytical standpoint, the really fundamental property is:
d/dx(ex) = ex
The second definition uses calculus, and is therefore more advanced in terms of the level of mathematical education required to understand it. However, it's also the reason it turns up everywhere in maths, including specifically here. Seen this way, the "compound interest" definition is really just a consequence of the more fundamental idea that ex is its own derivative - if you have money earning interest at 100% per year, then at any time the annual return on your money is going to be equal to the money you currently have, and so it's natural to look for a function which is its own derivative.
Depends what you consider the definition of e. Most people are introduced to it through the following identity:
lim(n -> inf) (1+1/n)n = e
However, from an analytical standpoint, the really fundamental property is:
d/dx(ex) = ex
There is a link between the two definitions when it comes to learning calculus. It comes in when establishing the derivative of logarithms.
The general logarithm is defined as: logb(x) is the value y such that by=x, b positive and not 1. Using the limit definition of the derivative:
d/dx logb(x) = lim[h→0] (logb(x+h)-logb(x))/h
= lim[h→0] (1/h)*logb(1+h/x)
= lim[h→0] logb((1+h/x)1/h)
= logb(lim[h→0] (1+h/x)1/h)
= (1/x)*logb(lim[h→0] (1+h/x)x/h)
= (1/x)*logb(lim[k→∞] (1+1/k)k),
where k=x/h. Now lim[k→∞] (1+1/k)k is defined to be e, and so
d/dx logb(x) = (1/x)*logb(e),
and defining ln(x) to be loge(x) gives
d/dx ln(x) = 1/x.
The derivative of ex now comes from the chain rule: Taking derivative of both sides of x=ln(ex) gives
1=(d/dx ex)*(1/ex),
which implies d/dx ex = ex.
I was curious about what the derivative of exp(exp(x)) is (where exp(x) is ex). It has been so long since I last solved any derivatives that I'm really, really rusty, but I came up with the answer exp(exp(x)+x).
In order to somewhat verify that the answer is correct, I calculated what the tangent line of exp(exp(x)) at x=0 would be assuming that solution is correct, and I used a graphing calculator to draw it. The tangent line would be exp(exp(0))+exp(exp(0)+0) = e+x*e. And it indeed results in a line that's tangential to the exp(exp(x)) curve at x=0.
Out of curiosity I also graphed the curve exp(x) and its tangent at x=0, which would be exp(0)+x*exp(0), ie. 1+x. The result looked correct.
I noticed that both tangent lines, ie. e+x*e and 1+x, intersect at x=-1.
This of course brings up the conjecture that the same is true for all curves of the form exp(exp(...(exp(x))...)). However, this hypothesis is incorrect because the tangent for exp(exp(exp(x))) does not intersect the x axis at x=-1.
So I was wondering what exactly is the pattern? If the tangent lines at x=0 of both exp(x) and exp(exp(x)) intersect at x=-1, what other curves of that form have the same property? What's the pattern? Or is that just a huge coincidence that's true only for those two curves?
There's a general formula here:
d/dx expn(x) = exp(expn-1(x)+expn-2x+...+exp2(x)+exp(x)+x)
Plugging this expression in for x=0, the functions exp(x), exp2(x), exp3(x), exp4(x) have gradients 1, e, ee+1, eee+e+1. This doesn't seem to make a particularly neat pattern on a graph, really.
All this e-chat reminded me of a relatively obscure property of e which turns up in the following problem:
A cheeky monkey is stealing bananas from a market stall. At the market, bananas come in boxes of a specific size. The monkey is very clever, and knows the vendor leaves his market stall unattended for a few minutes at the same time every day to pray, leaving a partially full box of bananas. At this time the monkey dashes to the box and takes it back to his lair, where he has his own box of the same size that he has also stolen from the vendor. He does this every day until his box is full of bananas. Show that, on average, it takes e days to fill the box.
The monkey is very clever, and knows the vendor leaves his market stall unattended for a few minutes at the same time every day to pray, leaving a partially full box of bananas.
As I'm familiar with this problem, I'll point out that the amount of bananas in the box is uniformly distributed on the interval [empty, full].
Put in more mathy terms, let f(x) be a uniform probability distribution function on the interval [0,1]. That is, f(x) = 1 if 0<x<1 and f(x) = 0 elsewhere. Values are selected from this pdf until their sum exceeds 1. Let the number of selections be N. Show that on expected value of N is e.
I've never actually tried to prove this. I'm going to guess that one way it can be done is with the convolution.
All this e-chat reminded me of a relatively obscure property of e which turns up in the following problem:
A cheeky monkey is stealing bananas from a market stall. At the market, bananas come in boxes of a specific size. The monkey is very clever, and knows the vendor leaves his market stall unattended for a few minutes at the same time every day to pray, leaving a partially full box of bananas. At this time the monkey dashes to the box and takes it back to his lair, where he has his own box of the same size that he has also stolen from the vendor. He does this every day until his box is full of bananas. Show that, on average, it takes e days to fill the box.
I'll assume the problem is one about selecting and adding values from a uniform distribution on [0,1] until their sum is greater than 1.
Given n variables x1, x2, ..., xn whose values are randomly selected from [0,1], what is the probability that x1+x2+...+xn<1? (*)
The answer to (*) is 1/n!. There are a few ways to show this. One is that the question is equivalent to finding the volume of an n-dimensional simplex whose vertices are (0,0,...,0), (1,0,...,0), (0,1,...,0), ..., (0,0,...,1). Using the determinant formula for simplex volume thus gives 1/n!. (Or you could just use integration.) Another way which doesn't require this formula, or calculus, is as follows: The answer to (*) is the same as answering the following question:
Given n variables y1, y2, ..., yn whose values are randomly selected from [0,1], what is the probability that y1<y2<...<yn? (**)
This is because the probability for (*) is formed by taking x1 in [0,1], x2 in [0,1-x1], x3 in [0,1-x1-x2], ..., and the probability for (**) is formed by taking y1 in [0,1], y2 in [y1,1], y3 in [y2,1], ..., where y1 corresponds to x1, y2 to x1+x2, y3 to x1+x2+x3, and so on. For (**), the probability must be 1/n!, since the particular ordering of y1<y2<...<yn is one of n! possible orderings of y1,y2,...,yn , each of which have the same probability.
So now that we know the answer to (*) is 1/n!, the probability that n values were selected by the time their sum is greater than 1 is 1/(n-1)! - 1/n! = (n-1)/n!. The expected number is then:
Sum{n from 1 to infinity} n(n-1)/n! = Sum{n from 2 to infinity} 1/(n-2)! = 1+1+1/2!+1/3!+... = e.
------------------------------------------------------------
By the way, about the Riddler problem of filling out the long division below with digits 0 to 9:
It can be solved as follows:
● c must be 0, since no subtraction takes place when its digit is brought down.
● www is 7 times uuu
● xxx, which is a multiple of uuu, is greater than www, since xxx plus yy is a 4-digit number, but www plus a 3-digit number is a 3-digit number. However xxx is less than vvvv and zzzz, also multiples of uuu.
● It follows that xxx is 8 times uuu and vvvv=zzzz is 9 times uuu. So b=8 and a=d=9.
● Since xxx which is 8 times uuu is a 3-digit number, then uuu is between 112 and 124.
● So yy is less than 13.
● But xxx+yy is a 4-digit number.
● So xxx which is 8 times uuu is between 988 and 999.
● Only possibility is uuu=124.
The unique solution is thus:
I like this problem because the fact that it has a unique solution is not so obvious, yet all the necessary information is based on the structure of the long division presented.
The other Riddler problem wasn't so fun. I took the solution here from yesterday's Riddler column. No claim (let alone proof) is given that this rearrangement into a square here is unique:
The Leibniz formula for pi is
4 * (1 - 1/3 + 1/5 - 1/7 + 1/9 - 1/11 + 1/13 + ...) = pi
One curious thing about this series is how incredibly slowly it approaches pi. For example, to get the 10 first decimal places of pi correct, you need about five billion terms.
This is in contrast with other methods, such as the continued fraction for pi, which approaches pi very rapidly. You only need a few terms to get a substantial amount of correct decimals.
I was wondering if there's a series that approaches pi even slower than the Leibniz formula.
I was able to find a French paper that provides this formula as: "The slowest and heaviest formula imaginable to access pi, developed to verify a hypothesis on the volume of the sphere"
I don't know how slowly it converges. It might be sub-logarithmic.
A formula the converges approximately as quickly as Leibniz formula is the Wallis Product formula. This formula also has logarithmic convergence.
2/1 * 2/3 * 4/3 * 4/5 * 6/5 ...
Hope this helps.
Build a man a fire, warm him for a day,
Set a man on fire, warm him for the rest of his life.
I suppose that any sequence can be made "slower" by making a variation of it with more terms (such as, for example, and I suppose, in the Leibniz formula rather than using odd numbers directly, make each term a sequence that converges to said odd number, or something), but I suppose that the spirit of my question was not really "can you take an existing formula and create a variant of it that has more terms". Rather, if there's a completely different unrelated formula that's slower. (Although, I suppose, "unrelated" may be too fuzzy of a requirement because many sequences approaching a given value can be converted into each other by applying some transformations.)
It's hard to make abstract ideas unambiguous, when dealing with mathematics.
I suppose that any sequence can be made "slower" by making a variation of it with more terms (such as, for example, and I suppose, in the Leibniz formula rather than using odd numbers directly, make each term a sequence that converges to said odd number, or something), but I suppose that the spirit of my question was not really "can you take an existing formula and create a variant of it that has more terms". Rather, if there's a completely different unrelated formula that's slower. (Although, I suppose, "unrelated" may be too fuzzy of a requirement because many sequences approaching a given value can be converted into each other by applying some transformations.)
It's hard to make abstract ideas unambiguous, when dealing with mathematics.
Huh. That's actually kind of interesting to me and I'd like to look into it but I'm a little busy. Let me try to formalize this.
Let a_n be a sequence whose corresponding series converges to A at some rate O(f(n)).
Let b_n be a sequence whose corresponding series converges to 1 at some rate O(g(n)). (It could converge to anything, but for the sake of simplicity, let's just normalize it so that it converges to 1.)
Define a new sequence a'_n to be such that
a'_0 = a_0*b_0
a'_1 = a_0*b_1
a'_2 = a_1*b_0
a'_3 = a_0*b_2
a'_4 = a_1*b_1
a'_5 = a_2*b_0
...
and so on. I'm not quite sure how to write this in closed form, but the basic pattern is that for every k, a_i*b_(k-i) is represented consecutively.
This new series, a', surely converges to A because each of the terms a_n is represented as a series in b_n. At what rate does a' converge to A?
Edit: Some random musings on the above problem: I wanted to throw out a guess as to what the rate of convergence should be, but nothing is coming to me. The one thing that I'm comfortable guessing is that the rate may be divided by n^2, since the size of the partitions increases as n^2. The bigger piece, however, is the interplay of f and g. As g increases, the rate of convergence should also increase, but it is not at all obvious how. Do we take f(n)*g(n) or perhaps one of the composite functions, f(g(n)) or g(f(n))? No, none of those make sense because they allow for a series split in this way to converge faster than our original series. I guess I also see an issue with attempting to order the rate of convergence. We would intuitively take O(exp(n)) to be faster than O(n^a), which is still faster than O(log(n)) for a few examples. But what about O(1)? That is a trivial series that converges after a finite number of terms. For example, we could have b_0 = 1 and b_k = 0 for k>0, giving us the fastest possible convergence. Does O(1) break the intuitive pattern I've outlined above?
These thoughts lead me to believe that this problem may be ill-posed.
Edit 2: Upon yet further reflection, I've realized I don't really know how to properly apply big-O notation to series convergence. I'll need to reformulate the question. I'm still busy, though.
Well obviously if ∑an converges to π and f:{0,1,...}→{0,1,...} is an increasing function, then so does ∑bn where by=af-1(y) if y is in the range of f and by=0 otherwise. So we can take f(n) to be as fast-increasing as we can conceive and ∑bn would converge as slowly.
But that's cheating. To make things a little less trivial, let's assume the sequence {|an|} is always decreasing (but not zero). We can rewrite cn=1/|an| where {cn} is always increasing.
Now if the terms an are always positive, then ∑an=∑1/cn is absolutely convergent. The corresponding sequence {cn} can't increase too slowly or else the sum would diverge. At least cn would need to go to ∞, but that's not enough; for example the harmonic series (1+1/2+1/3+...) diverges. In fact, cn would have to grow faster than linearly in n for the same reason the harmonic series diverges. So already it cannot converge slower than the Leibniz formula if it is absolutely convergent.
So another obvious approach is to allow an to alternate in sign, so that ∑an=∑(-1)n/cn. In this case, cn can grow as slowly as possible (since in this case, all that is required for convergence is cn→∞). For example, cn=ln(ln(n+1)+1) would cause the summation to converge extremely slowly, cn=ln(ln(ln(n+1)+1)+1) slower still, and so on. Unfortunately, we know very little about what these series converge to.
These series (when cn grows linearly or slower) are obviously conditionally convergent. The Riemann Series Theorem says that you can rearrange a conditionally convergent series to converge to any real number you choose or even diverge. Thus there is a rearrangement of ∑(-1)n/cn that converges to π, and would converge very slowly. The problem is that we have no clue what this rearrangement is.
So other than the Leibniz formula, I can't think of another formula that converges to π that is slower with {|an|} always decreasing. I thought of the Dirichlet eta function (alternating Riemann zeta function) but don't know any rational numbers in (0,1) that would make it converge to anything related to π.



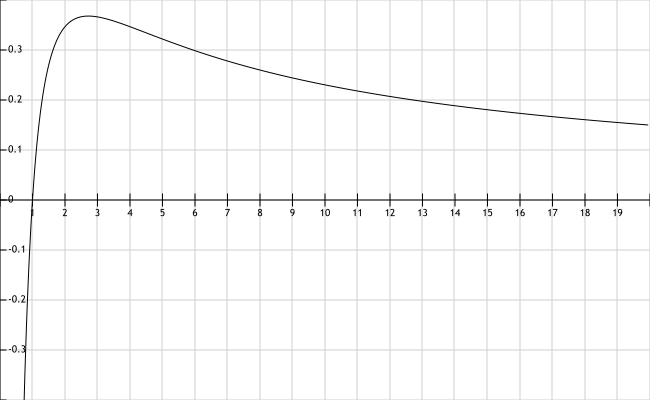 So the equation ln(x)/x = c has two solutions x1, x2 whenever 0 < c < 1/e (the maximum of ln(x)/x is at x=e with a value of 1/e; this is proved with calculus; ln(x)/x → 0 as x → ∞ as well), with 1 < x1 < e, and x2 > e. For example, when c = ln(2)/2, the two solutions are x1=2 and x2=4.
In fact, these two solutions are given exactly by x1 = e-W(-c) and x2 = e-W-1(-c), respectively, where W(x) and W-1(x) are branches of the
So the equation ln(x)/x = c has two solutions x1, x2 whenever 0 < c < 1/e (the maximum of ln(x)/x is at x=e with a value of 1/e; this is proved with calculus; ln(x)/x → 0 as x → ∞ as well), with 1 < x1 < e, and x2 > e. For example, when c = ln(2)/2, the two solutions are x1=2 and x2=4.
In fact, these two solutions are given exactly by x1 = e-W(-c) and x2 = e-W-1(-c), respectively, where W(x) and W-1(x) are branches of the 
 That is the easy problem. The hard problem is Riddler Express below.
Riddler Express: Cut the shape below into three pieces and reassemble them into a square.
That is the easy problem. The hard problem is Riddler Express below.
Riddler Express: Cut the shape below into three pieces and reassemble them into a square.
 I have a solution for Riddler Classic but I still haven't figured out Riddler Express yet.
I have a solution for Riddler Classic but I still haven't figured out Riddler Express yet.



 I don't know how slowly it converges. It might be sub-logarithmic.
A formula the converges approximately as quickly as Leibniz formula is the Wallis Product formula. This formula also has logarithmic convergence.
2/1 * 2/3 * 4/3 * 4/5 * 6/5 ...
Hope this helps.
I don't know how slowly it converges. It might be sub-logarithmic.
A formula the converges approximately as quickly as Leibniz formula is the Wallis Product formula. This formula also has logarithmic convergence.
2/1 * 2/3 * 4/3 * 4/5 * 6/5 ...
Hope this helps.