This one may also be a matter of "looking it up": Find an example of a real-valued function of a real variable that is nowhere continuous and yet still satisfies the conclusion of the intermediate-value theorem (that is, the image of an interval is another interval), thereby showing that the converse of the intermediate-value theorem is false in any reasonable sense.
Yup, the sketch of my original solution was:
Let f(z) satisfy the given conditions with f(z) = sum(anzn, n>=0).
Construct g(z) = sum(anz-n,n>=1)
The conditions imposed on f imply that g's Laurent series converges for 0<|z|<inf and |g(z)| <M>=0 on a circle of radius e>0, the absolute value of the integral will be less than M*l = 2pi*M*e, for every e>0, so it must be 0.
Since the integral vanishes, the residue of zng(z) also does, and this implies that all an's with the exception of a0, vanish. This requires f to be constant, contradicting the initial hypothesis.
I haven't touched complex analysis for quite a while, so I didn't remember right away that this was a classical problem, the proof of Liouville's theorem is much more simple than what I did...
This one may also be a matter of "looking it up": Find an example of a real-valued function of a real variable that is nowhere continuous and yet still satisfies the conclusion of the intermediate-value theorem (that is, the image of an interval is another interval), thereby showing that the converse of the intermediate-value theorem is false in any reasonable sense.
Correct. It is a matter of looking it up.
http://en.wikipedia.org/wiki/Conway_base_13_function
If you want it defined on the whole real line, then define the function to be the Conway base 13 function of the fractional part if not an integer, or 0 if it is an integer.
I looked a lot of threads back and saw no problem in abstract algebra, so here goes one. It can also be solved by looking it up, if you know groups well:
Let G be a finite nontrivial group such that, for every two elements a and b in G different from the identity, there's an element c in G satisfying b = c-1ac. Prove that |G|=2.
More of a maths related question.
If you got a 1 in X chance of winning the lottery, then you'll win it once on average every X tries. However, I think that contrary to our intuition, if you try it exactly X times, you'll have a 1-1/e or 63.21% chance of having won it at least once by then. Why is this? It'd have to do with the fact that if you are unlucky, numbers can go arbitrarily high, but if you are lucky, they can't get arbitrarily low (also winning twice at <X only counts as one win). So the average ends up being X, even though the chance of having won at least once at X tries is well above 50%. You can write a simple program to verify this for yourself. Alternatively, you can calculate the chance of repeated failure by (1-1/X)^tries, so the chance of having won at least once at X times is 1-((1-1/X)^X) and that seems to be the same as 1-1/e. The chance of already having won at least once 37% of the way is 1-1/(e^0.37)
success = 0;
for (int j = 0; j < 1000000; j++)
{
for (i = 0; i < 12345; i++)
{
x = r.Next(12345);
if (x == 1)
{
success++;
break;
}
}
}
Console.WriteLine("Won before average {0}% of the time", 1.0 * success / 10000);
Another interesting question is how many tries do you have to make to have a cummulative Y/Z chance of having won at least once. According to my experiments, you have to try X*LN(Z/(Z-Y)) times. So for a 37% chance of winning at least once, you'd need to try X*LN(100/63) times. A 50% chance is given by X*LN(2/1), a 25% chance by X*LN(4/3), a 75% chance at X*LN(4/1). How can this be explained? What do I need to google for to read up more on this really captivating subject?
(Sorry for starting a new page with this still unanswered):
p4wn3r wrote:
I looked a lot of threads back and saw no problem in abstract algebra, so here goes one. It can also be solved by looking it up, if you know groups well:
Let G be a finite nontrivial group such that, for every two elements a and b in G different from the identity, there's an element c in G satisfying b = c-1ac. Prove that |G|=2.
More of a maths related question.
If you got a 1 in X chance of winning the lottery, then you'll win it once on average every X tries. However, I think that contrary to our intuition, if you try it exactly X times, you'll have a 1-1/e or 63.21% chance of having won it at least once by then. Why is this? It'd have to do with the fact that if you are unlucky, numbers can go arbitrarily high, but if you are lucky, they can't get arbitrarily low (also winning twice at <X only counts as one win). So the average ends up being X, even though the chance of having won at least once at X tries is well above 50%. You can write a simple program to verify this for yourself. Alternatively, you can calculate the chance of repeated failure by (1-1/X)^tries, so the chance of having won at least once at X times is 1-((1-1/X)^X) and that seems to be the same as 1-1/e. The chance of already having won at least once 37% of the way is 1-1/(e^0.37)
That's correct. First of all, when we define the probability of something to be 1/X, it means that if you keep trying the experiment, the ratio of success/total will get closer and closer to the value of 1/X.
As you can see, the definition only says something useful when the amount of tries tends to infinity, it says nothing about the probability of getting a success before X tries (the expected value), this information is contained in a function called probability distribution function, it varies greatly depending on the process you're considering.
For your case, the distribution is the geometric distribution. However, when the probability p of a success is very small, you can ditch it and approximate it with a continuous one, the exponential distribution using the parameter lambda = p.
Notice that 1/lambda is in fact the moment where you expect the success to occur, for lambda = 1/X, that value is X. Basically, what you said is that the probability of getting the success before X=1/lambda is 1 - 1/e. This value can be found by integrating the exponential distribution (or plugging x = 1/lambda in the accumulated distribution).
The wikipedia article says F = 1 - e^(-x*lambda), and for x = 1/lambda, in fact F = 1 - 1/e.
Now, if you're after a fixed ratio F, you can invert the formula to find -x = (1/lambda)*ln(1-1/F) or x = (1/lambda)*ln(1/(1-1/F)).
In your post, lambda = 1/X and F = Y/Z. That gives the same formulas you offered. So, it seems you deduced the exponential distribution without ever hearing about it. Congratulations!
EDIT: If this question is related to this:
Kuwaga wrote:
Show how and why 0,5^(x*y/ln(2)) approximates (1-x)^y for most values of 0 < x < 1 and y being any natural number.
It works especially well for large y, in that case it works even for 0 < x < 2.
The way you wrote it, it's false. They don't approximate each other when y tends to infinity. The approximation works if x is very small, in other words x tending to 0 (which is the condition to use the exponential distribution).
In that case, (1-x)^y = {(1-x)^(1/x)}^(xy), what's inside the brackets tends to 1/e, plugging 1/e there gives you e^(-xy) = 0.5^(x*y/ln(2))
I looked a lot of threads back and saw no problem in abstract algebra, so here goes one. It can also be solved by looking it up, if you know groups well:
Let G be a finite nontrivial group such that, for every two elements a and b in G different from the identity, there's an element c in G satisfying b = c-1ac. Prove that |G|=2.
This is easy.
Two elements a,b satisfying b = c-1ac for some c in G are in the same conjugacy class by definition. Since this holds for any a,b in G other than the identity, then there is a conjugacy class of size |G|-1. From the Orbit-Stabilizer Theorem (using conjugacy as a group action), the size of any conjugacy class divides the order of the group. So |G|-1 divides |G|. This implies |G|=2.
I have that one and two other solutions, they prove that G is abelian, and since conjugacy classes in abelian groups consist of only one element, the conditions will require that all non-identity elements of G are equal, thus |G|=2.
a) G, like any other finite group, has an element of prime order. Since all elements are in the same conjugacy class, they all have the same order, so G is a p-group and, thus, has a nontrivial center, from the conditions we get that this center consists of all elements of G. Therefore, G is abelian.
b) This is the most elementary, but the most difficult: Pick an element a in G\{e}. For G, the map f(c) = c-1ac between G\{e} and G\{e} is surjective, but since the sets are finite, it's bijective. But f(a)=f(a2)=a. So, it must be that a2=e for every element in G. From here, (ab)(ab) = (ab)b-1a-1. Since the inverse is unique, ab = b-1a-1 = b2b-1a-1a2 = ba, and G is abelian.
A star has two planets, planet A and planet B, which are distance a and b, respectively, from the star, and planet B is closer to the star than planet A (b<a). Assume the planets orbit in the same plane and the orbits are circular. An observer on planet A is looking toward planet B. Assume the brightness of planet B is directly proportional to the fraction of the visible surface that is in light (which is directly proportional to 1+cos(θ), where θ is the angle formed by star-planetB-planetA) and inversely proportional to the square of the distance between the two planets, where the distance is d. So the brightness functions as a rate of (1+cos(θ))/d2. Find the distance d which maximizes this quantity.
By the way, the image above, for what it implies in real life, is obviously far from drawn to scale.
Hi I have no idea what I'm doing
a > b
cos(theta) =(b^2 + d^2 - a^2)/2bd (by cosine rule)
B = (1+(b^2 + d^2 - a^2)/2bd)/d^2
B = 1/d^2 + (b^2+d^2-a^2)/2bd^3
B = 1/2bd + 1/d^2 + (b^2-a^2)/2bd^3
Not sure what to do from here, but I'll try. We can see that when we increase d, the first two components are lowering the brightness, but the last one will raise the brightness (since a > b, b^2-a^2 is negative). Where B's peak will be will depend on the relationship between a and b.
We can differentiate this with respect to d and look for roots. This will let us find local maxima and local minima.
B = (1/2b)*d^(-1) + d^(-2) + ((b^2-a^2)/2b)*d^(-3)
dB/dd = -(1/2b)/d^2 - 2/d^3 - 3(b^2-a^2)/2bd^4
let dB/dd = 0
3(b^2-a^2)/2bd^4 = - (1/2b)/d^2 - 2/d^3
-3(b^2-a^2)/2b = d^2/2b + 2d
-3(b^2-a^2) = d^2 + 4db
Now we have to complete the square
d^2 + 4db + 4b^2 = b^2 + 3a^2 = (d+2b)^2
d + 2b = +/-sqrt(b^2 + 3a^2)
d = +/-sqrt(b^2 + 3a^2) - 2b
are the roots of dB/dd, and thus the maxima/minima of B, where we should look to maximize the quantity B.
1) Prove that the smallest non-abelian group has order 6.
2) How many homomorphisms f : K -> Z4 are there? (K stands for the Klein four-group)
3) Let D be a group of order 2n, where n is odd, with a subgroup H of order n satisfying xhx-1=h-1 for all h in H and all x in D\H (the set of elements in D but not in H). Prove that H is abelian and that every element of D\H has order 2.
Patashu is on the right track, but the conclusion isn't complete.
Using notation above, B=(-d2+2bd-a2-b2)/2bd3 and dB/dd=(-d2-4bd+3a2-3b2)/2bd4.
We check when dB/dd>0, dB/dd=0, and dB/dd<0. By completing the square on the numerator of dB/dd, we have dB/dd=(-(d+2b)2+3a2+b2)/2bd4. If we solve dB/dd>0, we get 3a2+b2>(d+2b)2, or d is in the range (-2b-sqrt(3a2+b2),-2b+sqrt(3a2+b2)). Since d is only valid when a-b≤d≤a+b, we can restrict d to that range. We only consider the numerator of dB/dd because the denominator is always positive.
If we plug in a-b into 3a2+b2-(d+2b)2, we get 2a2-2ab=2a(a-b)>0, and so dB/dd>0 always when d=a-b.
If we plug in a+b into 3a2+b2-(d+2b)2, we get 2a2-6ab-8b2=(1/2)(4a2-12ab-16b2)=(1/2)((2a-3b)2-25b2). If a<4b, then dB/dd<0. If a≥4b, then dB/dd≥0.
* In the first case (a<4b), since dB/dd>0 at a-b and dB/dd<0 at a+b, then exactly one local maximum -2b+sqrt(3a2+b2) lies in the range (a-b,a+b) and so the maximum occurs at distance d=-2b+sqrt(3a2+b2).
* In the second case (a≥4b), there is no local maximum on (a-b,a+b) and the derivative is positive on this range, so the maximum occurs at distance d=a+b.
This problem was motivated by the greatest brilliancy of Venus, which occurs about 5 weeks on either side of inferior conjunction, of which the position roughly indicated in the above image is one of the two positions relative to Earth. On the other hand, greatest elongation of Venus (θ=90°) occurs about 8 weeks on either side of inferior conjunction. So Venus is brightest at its crescent phase (θ>90°). On the other hand, Mercury is (usually) brightest at its gibbous phase (θ<90°). Using the assumptions of the problem above, greatest brilliancy coincides with greatest elongation when b=a/sqrt(5)≈0.447a. For comparison, distances from the Sun are 1AU for Earth, ≈0.72AU for Venus, and the range from ≈0.31AU to ≈0.47AU for Mercury.
Sorry for the wall of text.
1) Prove that the smallest non-abelian group has order 6.
The symmetric group on 3 elements (S3) has order 6 and is non-abelian, since (cycle notation) (12)(13)=(132) and (13)(12)=(123).
For a group G with a smaller number of elements:
|G|=1: That is the trivial group, which is abelian.
|G|=2: That is Z2, which is abelian.
|G|=3: That is Z3, which is abelian.
|G|=4: There are two groups. If there is an element of order 4, then it is Z4, which is abelian. Otherwise, the group is K=Z2xZ2, which is abelian.
|G|=5: That is Z5, which is abelian.
p4wn3r wrote:
2) How many homomorphisms f : K -> Z4 are there? (K stands for the Klein four-group)
K=<(1,0),(0,1)>, so the action of f on (1,0) and (0,1) uniquely determine the homomorphism. In general, if f:G->H maps g to h, then the order of h in H divides the order of g in G. So (1,0) can be mapped to 0 or 2 in Z4 and (0,1) can be mapped to 0 or 2 in Z4. This gives 4 homomorphisms.
p4wn3r wrote:
3) Let D be a group of order 2n, where n is odd, with a subgroup H of order n satisfying xhx-1=h-1 for all h in H and all x in D\H (the set of elements in D but not in H). Prove that H is abelian and that every element of D\H has order 2.
Let h1,h2 in H and x in D\H. Then h1h2=xh2-1h1-1x-1=xh2-1x-1xh1-1x-1=h2h1. So H is abelian.
Let x in D\H and h in H, h≠e, where e is the identity. Then x2hx-2=xh-1x-1=h. Since h≠h-1 (otherwise h has order 2, but |H| is odd, contradiction), then x2 is not in D\H, so x2 is in H. Then x2=xx2x-1=x-2. So x4=e. If x2≠e, then x2 in H has order 2, again a contradiction (similar to first bracket text). So x2=e. Since x≠e, then x has order 2.
1) Prove that the smallest non-abelian group has order 6.
The symmetric group on 3 elements (S3) has order 6 and is non-abelian, since (cycle notation) (12)(13)=(132) and (13)(12)=(123).
For a group G with a smaller number of elements:
|G|=1: That is the trivial group, which is abelian.
|G|=2: That is Z2, which is abelian.
|G|=3: That is Z3, which is abelian.
|G|=4: There are two groups. If there is an element of order 4, then it is Z4, which is abelian. Otherwise, the group is K=Z2xZ2, which is abelian.
|G|=5: That is Z5, which is abelian.
I don't like this, since you just list the groups without proving they are the only ones at that order. Citing a result like Lagrange's theorem would be nice.
Anyway, for a group of prime order p, the element is either the identity or has order p, so the only possible group is cyclic and, thus, abelian. That removes groups of order 2, 3 and 5.
For the group of size 4, Lagrange's theorem restricts the order to 1, 2 or 4. If there's an element of order 4, then the group is cyclic and abelian. If there isn't, a2=e for all a. And from this we deduce that the group must be abelian, since ab(ab) = abb-1a-1, ab = b-1a-1 = b2b-1a-1a2 = ba.
For (2) I used the first isomorphism theorem, but it's basically the same thing. And for (3), our solutions are almost identical.
OK, here goes.
Let m, n be integers with m≤n. Let S be the set of permutations of {1,...,n} consisting only of cycles of size less than or equal to m. Prove that m! divides |S| (the size of S).
Well, if a permutation has a k-cycle, with k > m, you can take m numbers in the cycle, permute them and you'll get a different cycle and thus, a different permutation, as long as the permutation done on the m numbers you chose is different. So, given a permutation that has a k-cycle, you can always extend it so that you have m! ones. So, the amount of permutations with a k-cycle is divisible by m!. Since that's true for every k > m, the amount of permutations not in S is divisible by m!. Since the sum of the elements of S with its complement is n!, which is also divisible by m!, the number of permutations in S must also be divisible by m!.
Is this enough or is it necessary to express the symmetry with group actions in Sn?
You don't need to express symmetry of Sn, but I don't understand what you mean by this: "given a permutation that has a k-cycle, you can always extend it so that you have m! ones".
I'd express it like this:
Permutations in Sn\S have at least one cycle of length k, k>m. Two permutations p and q are in the same class if q can be formed from p as follows: Let C be the cycle in p containing the smallest number which is contained in a cycle of length greater than m. In C, take the smallest m numbers. Then q is formed from p by permuting these m numbers. Note that every permutation of these m numbers results in a distinct permutation, because at least one number in C is fixed.
The elements of Sn\S are partitioned by these classes, since every permutation is contained in exactly one class. Every class has size m!. Therefore, m! divides |Sn\S|=|Sn|-|S|. Since m! divides |Sn|, then m! divides |S|.
Here's another question:
Let n>3 and k>2. Take a sequence of integers (ai) of length n, where each integer is between 0 and k inclusive. Apply the following step to this sequence over and over:
Take any four consecutive numbers in the sequence and call them a,b,c,d from left to right. Do one of the following two:
* Replace a with a-1, b with b+2, and d with d-1, provided all numbers remain between 0 and k.
* Replace a with a+1, c with c-2, and d with d+1, provided all numbers remain between 0 and k.
Prove that eventually, the whole procedure must come to an end (only finitely many steps can be taken) no matter what.
You don't need to express symmetry of Sn, but I don't understand what you mean by this: "given a permutation that has a k-cycle, you can always extend it so that you have m! ones".
You're right, that sentence is problematic, I meant that if you have the 4-cycle (1234) you can generate, say, 3! different ones, by permuting the numbers 1,2,3 and get (1234), (1324), (2134), (2314), (3124) and (3214). So, the assumption that 3! doesn't divide the set of 4-cycles is contradictory, since you can pick everyone of them and generate 3! ones. Anyway, the way you expressed it is clearly better.
FractalFusion wrote:
Let n>3 and k>2. Take a sequence of integers (ai) of length n, where each integer is between 0 and k inclusive. Apply the following step to this sequence over and over:
Take any four consecutive numbers in the sequence and call them a,b,c,d from left to right. Do one of the following two:
* Replace a with a-1, b with b+2, and d with d-1, provided all numbers remain between 0 and k.
* Replace a with a+1, c with c-2, and d with d+1, provided all numbers remain between 0 and k.
Prove that eventually, the whole procedure must come to an end (only finitely many steps can be taken) no matter what.
Consider a function f taking the sequence as an argument, such that f = sum( min(2a,k-b,2d) + min(2k-2a,c,2k-2d) ), where the summation is done for each consecutive tuple (a,b,c,d).
We'll consider the values of the function before and after a step of the algorithm. Suppose you applied the operation to a tuple (a,b,c,d). Suppose the operation increased a term in the summation. In order to increase the value of min(r,s,t) you have to increase both r,s and t. For our function f, that implies that both a and d must be different, but in only one term a and d are changed, and that term is the one that corresponds to the tuple where you applied the algorithm.
Looking at this particular term, if you used the first option:
term = min(2a-2,n-b-2,2d-2) + min(2n-2a+2,c,2n-2d+2)
And for the second:
term = min(2a+2,n-b,2d-2) + min(2n-2a-2,c-2,2n-2d-2)
In both cases, one of the minimums is less than or equal to before (one of the arguments not changed) and the other is certainly less than before. Thus, that term decreases after we apply the algorithm.
So, after the operation one of the terms in f decreases, while the others cannot increase. So, f decreases overall. The restriction that all numbers in the sequence are between 0 and k makes f always return a natural number. So, if it were possible to apply these operations indefinitely, one could construct a strictly decreasing sequence of natural numbers, violating the well-ordering property of N. So, there must always be a situation where the algorithm can no longer be applied after finitely many steps.
(This is not very didactic, but I'm in a hurry right now)
Consider a function f taking the sequence as an argument, such that f = sum( min(2a,k-b,2d) + min(2k-2a,c,2k-2d) ), where the summation is done for each consecutive tuple (a,b,c,d).
You're on the right track, but there is a problem with the statement "In order to increase the value of min(r,s,t) you have to increase both r,s and t." The value of min(r,s,t) can increase even if only one of r,s,t is increased; as long as it is the smallest of the three values when it increases.
It is a function f though. There is also a solution by casting the problem in terms of polynomials that I overlooked when I stated the problem, but doing that way is much harder, I think.
Heh, that function was one of the first I constructed looking at n=4 and tried to extend it to larger sizes, I should have at least double-checked a generalization I made in ten minutes before posting it. Anyway, I solved it using a totally different function.
It's f = sum(i*a_i)
Every operation does one of the following:
n*a + (n+1)*b + (n+2)*c + (n+3)*d -> n*(a-1) + (n+1)*(b+2) + (n+2)*c + (n+3)*(d-1)
n*a + (n+1)*b + (n+2)*c + (n+3)*d -> n*(a+1) + (n+1)*b + (n+2)*(c-2) + (n+3)*(d+1)
For the first case, f_new - f_old = -n + 2n + 2 - n - 3 = -1
and for the second, f_new - f_old = n - 2n - 4 + n + 3 = -1
So, it's decreasing. The motivation behind it is that I found out that repeating the procedure on a tuple indefinitely, you'd be reducing c and increasing b, like carrying units from one end of the array to the other, so I made a function that gave more weight to the numbers if they were at the end. This one was the first one I tried and it turned out much more elegant than I thought it would.
Can you share your polynomial solution?
Good job, p4wn3r. I had the same function f (actually, I used f=sum((n+1-i)*a_i), because I tend to think big-endian when it comes to math) and intentionally designed the problem around that function.
I was hoping you wouldn't put down the polynomial solution; though, if you did, I would have just thrown in another option, something like "a → a+1, b → b-2, c → c+2, d → d-1", to force you to do it the way I intended. :p
The polynomial solution is as follows:
Suppose that the process does not end in a finite number of steps. Since there are a finite number of states for the sequence, then there exist a positive number of steps that take a sequence to itself. Consider the sequence as the coefficients of a polynomial in x, where the numbers at the beginning of the sequence represent the coefficients of the highest degree terms in the polynomial. Because the two possible options apply always to four consecutive numbers in the sequence, we can write:
(-x3+2x2-1)f(x)+(x3-2x+1)g(x)=0
where f and g are nonzero polynomials with nonnegative coefficients. Any nonzero polynomial with nonnegative coefficients, when evaluated at any x>0, gives a positive number. Therefore, -x3+2x2-1 and x3-2x+1 must have opposite signs or both be zero at all evaluations x>0. Plug in x=1.1, and you get 0.089 for the first and 0.131 for the second, which is a contradiction. Therefore the process must end in a finite number of steps.
This argument can be applied to other pairs of polynomials as well, such as -x3+3x2-1 and x3-3x+1. However, this does not apply to -x3+x2-1 and x3-x+1; indeed, it is possible in this case for the process to go on forever.
Say we have a codeword of length N=2n characters, which can take the value of 0 or 1. Lets say we want to change it to a pattern of alternating d-tuples of 0 or 1s, for divisors d|N. For example using N=12 we have the possible patterns being:
000000000000
101010101010
110011001100
111000111000
111100001111
111111000000
Now, when changing from one of these patterns to another, there are some numbers which we need to change, and others we can leave alone. Changing from our initial state to strings of 4 for example would require 4 (or 8) changes. What's interesting though, is that if you only change to the next one in the series, IE to the pattern associated to the next divisor of N, the amount of changes (IE hamming distance) is a constant value, n. In this case, changing the pattern in the order presented here will always require 6 changes, why?
Why is it that when going from one divisor to the next, ie from dx to dx+1, the associated patterns will always (?) have a Hamming Distance of n?
0101010101
0011001100
0000011111
etc





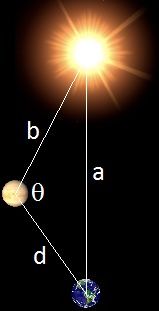 A star has two planets, planet A and planet B, which are distance a and b, respectively, from the star, and planet B is closer to the star than planet A (b<a). Assume the planets orbit in the same plane and the orbits are circular. An observer on planet A is looking toward planet B. Assume the brightness of planet B is directly proportional to the fraction of the visible surface that is in light (which is directly proportional to 1+cos(θ), where θ is the angle formed by star-planetB-planetA) and inversely proportional to the square of the distance between the two planets, where the distance is d. So the brightness functions as a rate of (1+cos(θ))/d2. Find the distance d which maximizes this quantity.
By the way, the image above, for what it implies in real life, is obviously far from drawn to scale.
A star has two planets, planet A and planet B, which are distance a and b, respectively, from the star, and planet B is closer to the star than planet A (b<a). Assume the planets orbit in the same plane and the orbits are circular. An observer on planet A is looking toward planet B. Assume the brightness of planet B is directly proportional to the fraction of the visible surface that is in light (which is directly proportional to 1+cos(θ), where θ is the angle formed by star-planetB-planetA) and inversely proportional to the square of the distance between the two planets, where the distance is d. So the brightness functions as a rate of (1+cos(θ))/d2. Find the distance d which maximizes this quantity.
By the way, the image above, for what it implies in real life, is obviously far from drawn to scale.



